Introduction
使用计算机计算和现实计算有一个显著差别:计算机计算的精度是有限制的。我们有不同的数据结构,带来不同的计算精度。数值分析这门课要求我们求出精度足够好的结果。它会告诉我们一些近似算法,同时也告诉我们,什么时候它们能用,什么时候又不能用。
我们轻而易举地就能想清楚加减乘除的原理。然而,我们可能没有注意, sin,cos,tan,ln 是怎么实现的?数值分析这门课可以告诉我们背后的原理。
一个自然的想法:泰勒展开
数学上的准备
怎么求一个积分?简单的想法是把被积函数泰勒展开转化成多项式,然后利用其便于求积分的特性求解。然而,泰勒展开往往是无限的,这就需要我们规定一个提前结束的时机,这也引入了一个相当于泰勒余项(Remainder)的误差。这个误差就是我们需要注意的。
而且,一个棘手的点是:我们没有办法直接和真值进行比较!
另一个棘手的点是:每一个数值本身都与它自己的真值有误差,这也引入了新的误差!我们需要为每一个数据保留多少位,这也相应地成为了一个问题。
误差 Errors
- Truncation Error:与时间有关的一个误差。它代表近似数学引入的误差。
显式的操作,经典的就是一个 for 循环
- Roundoff Error:与空间有关的一个误差。它代表数字在计算机中的表达和数字本身的误差。
数据背后的误差
为了讨论方便,我们用十进制来表示数字。对于一个不能直接以有限数位表示的数字,有两种方式处理精度:
- 四舍五入(Rounding)
- 直接砍掉精度数位后面的位数(Chopping)
- 往上取
大学老师给分(不是)
误差也分为绝对误差(absolute error)和相对误差(relative error)
而有效数字(siginificant digits)应该是一个相对误差概念。可以注意到,对应数值的部分被移到了科学计数法中的指数部分。
有了有效数字的概念,我们应该把数字 0.123 看成 0.123±ϵ1 使用四舍五
入的方法时,有效数字 0.1 的相对误差是 50%
那么,有一个现象,就是两个相近的数字相减之后,有效位数减小时,相对误差会显著增加。
将一个数除以一个很小的数,绝对误差会放大。这一点是符合直觉的。一个想法是把绝对误差看成两个数字的函数,然后取关于分母的导数,如果导数很大,那么就说明分母的轻微变化会带来较大的变化,也就是较大的误差。对于相对误差,也可以尝试以这样的方法进行分析。
计算的约化也要注意,计算机是每一个单元运算都会进行约化的,不能直接对最终结果进行约化。
也正是因此,虽然对单个数字而言,Rounding 会更精确,但是对于一个一连串的算式而言,未必。
我们此时也自然地想到,解不是确定值,也可能不是个区间,而应该是一个概率密度分布中的某个可能值。
也还是因此,对于同一个算式的不同表达,比如将一个算式通过一些方式结合,分配,也可以导致不同的误差。减少乘除的次数,有可能减少误差。减少单元计算的数量,也有可能减小误差。
数学上等价,不等于数值分析方法上等价!
我们可以手动求导来分析误差,也可以用一些自动求导的工具来分析计算式的误差。
算法和收敛 Algorithms and Convergence
当一个算法中,原始数据的较小变化只引起较小的终解的变化时,它是 stable 的;否则,它是 unstable 的。当它对于某些原始数据 stable 时,它是 conditionally stable 的。
设初始误差为 E1,当做连续的 n 次操作时,如果误差 En 约为 E1 的常数倍时,说误差的增长是 linear 的。如果 En 约为 E1 的以常数为底的指数倍时,则说
误差的增长是 exponent 的。
一元方程的求解
二分法
能使用二分法的前提是可排序。比如说,复数就很难使用二分,因为它没有既定的序。
二分法一定要除以二吗?不一定。只要区间收敛就好。
- 取中间位置时应该用 p=a+2b−a。
- 判断取左边界还是右边界时,需要用
sign(),而非直接相乘看是否小于 0。
- 函数值需要考虑溢出问题。比如说,一个指数函数就容易出现溢出,即使它的横坐标是没溢出的。
如果二分法的区间取的过大,可能会忽略函数的根,如一个先增后减的区间,两侧都小于零,就会误认为中间没解了。
不动点迭代
把方程的根转化成一个等效的等式:f(x)=0⇔x=g(x)。g 的不动点是 f 的根。
不动点定理:Self
令 g 是一个在 [a,b] 连续的函数,且在其中 g(x)∈[a,b]。若对于它的导函数
g′,存在一个常数 k∈(0,1) 使得开区间内任意的 x,有 ∣g′(x)∣≤k,则对任意的 p0∈[a,b],序列 pn=g(pn−1) 收敛到唯一的不动点 p∈[a,b]。
- 利用中间值定理,证明存在不动点。
- 利用中值定理,证明不动点唯一。
- 利用值域被定义域包含的条件,保证迭代过程中,g(x) 的结果始终在定义域中。
- 利用中值定理,证明迭代确实是收敛于那个存在且唯一的不动点。
这里的存在一个 k∈(0,1) 很重要,这把 g′(x) 和 1 隔开了,避免了极限为 1 的情况。
看证明是有利于记忆定理的。在看证明的过程中,可以理解每一个条件为什么被需要。
数值分析中有一个特点,给出的公式往往是充分的。顶层应用时,即使没有满足定理的条件,但我们还是有可能选择相信它。而在底层处理时,我们才会格外注意它的必要性。
不动点定理:Corollary
如果 g 满足了不动点定理,那么迭代误差的范围为:
∣pn−p∣≤1−k1∣pn+1−pn∣,∣pn−p∣≤1−kkn∣p1−p0∣
牛顿法
牛顿法也属于一种不动点方法。它的思路是把一个非线性函数线性化。
0=f(p)≈f(p0)+f′(p0)(p−p0),p≈p0−f′(p0)f(p0)
定理
若 f 在 [a,b] 二阶连续,且存在 p∈[a,b] 使得 f(p)=0,f′(p)=0,那么
就存在一个 δ>0,使得任意初值 p0∈[p−δ,p+δ] 都可以满足
pn+1=pn−f′(pn)f(pn) 收敛到 p。
-
由 f′(p)=0 知 g(x)=x−f′(x)f(x) 在 p 的邻域中连续。
-
g′(x)=f′(x)2f(x)f′′(x) 在 p 的邻域中趋于零,只要 f′′(x) 连续
且有限。
-
利用不动点定理知存在一个邻域使得收敛。
作业-2
P54-T13
找到一个迭代次数的范围,使得使用二分法解 [1,2] 上的方程 x3−x−1=0 时,解
的精确度有 10−4。同时,给出这个解。
此题主要考虑的是二分法的误差范围。当对 [a,b] 进行二分时,第一次二分迭代的结果
为 a+2b−a,ϵ≤2b−a。易知,第 n 次二分迭代的误差
范围为 ϵ≤2nb−a,此处只需取 n=14。具体求解过程略。
P54-T15
令 pn=∑k=1nk1,证明 pn 是发散 diverge 的,即使
limn→∞(pn−pn−1)=0。
这算是很经典的题目了,典型的方法有积分放缩。这里则采取证明连续多项的和拥有固定下界的方法:
k1+k+11…+2k−11>k⋅2k1=21
因此总能找到 p2k−1>pk+21,故 pn 是发散的。
P64-T3
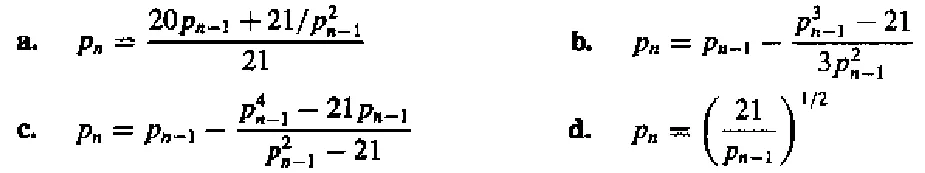
它们被用于计算 2131。根据收敛速度,将它们排序。假设 p0=1。
a. 这是一个比较普通的不动点方法,直接对
f(x)=2120x+x21
求导,得
f′(x)=2120−x32∈[−2122,76)
这看起来有些危险,我们不妨先迭代一次,得到 p1=2141,如果把这看成新的迭代起点,那么可以发现 f′(x) 的范围被控制住了,且拥有明确的上下界。那么,根据不动点定理的推论,可以得出误差的范围为
O(kn)≥O((f′(2141))n)≈O((f′(2))n)=O((8459)n)
b. 通过观察可以发现,这是牛顿法,原函数即为
f(x)=x3−21
关于牛顿法,有这样一件事情:
牛顿法的迭代公式为
pn+1=pn−f′(pn)f(pn)
设迭代终点为 r,记 ϵn=pn−r,则根据泰勒展开式,我们有:
ϵn+1=ϵn−f′(r)+f′′(r)ϵn+O(ϵn2)f′(r)ϵn+21f′′(r)ϵn2+O(ϵn3)=2f′(r)f′′(r)ϵn2
这也就是所谓的牛顿法具有二次收敛的性质,这个收敛速度已经很快了。
本选项就是一个二次收敛的样例。
需要注意的是,当出现重根, f′(x)=0,此时二次收敛不再成立。
c. 看起来很复杂,我们直接尝试代入,然后发现 p1=0,pk>1=0,可知压根收敛不到
2131。
d. 可以设 pn=21kn,则有
21kn=2121−kn−1⇒kn=21−kn−1⇒kn−31=−21(kn−1−31)
可知 kn 的误差为 O(21n),那么
pn=2131+O(2n1)=2131⋅(21O(2n1))≈2131(1+ln(21)O(2n1))
故误差为 O(2n1)。
综上,排序为 b>d>a>c。
P65-T19
- 利用不动点定理,证明当 x0>2 时,
xn=21xn−1+xn−11,for n≥1
收敛到 2,
- 利用“当 x0=2,0<(x0−2)2”,证明:当
0≤x0≤2,有 x1>2。
- 利用 (1), (2) 的结果,证明 (a) 中的式子收敛到 2,只要 x0>0。
- 记 f(x)=21x+x1,当 2<x≤x0 时,有 2<21x+x1<x0,即 f(x)∈(2,x0)。函数连续性显然;再由 f′(x)=21−x21∈(0,21) 知存在
k∈(0,1)。综上,已满足不动点定理。
- 题意估计是要我们配方,不过基本不等式易得了。
- 首先,利用 (2) 中结果,当 x0∈(0,2) 时,不妨先迭代一次,把迭代结果看成新的 x0>2。然后,由 (1) 易得收敛至 2。
x0∈(2,∞) 时亦然。
对迭代方法的误差分析
假设 {pn} 是一个收敛到 p 的序列,如果存在正常数 α 和 λ
使得
n→∞lim∣pn−p∣α∣pn+1−p∣=λ
则说 {pn} 对 p 的收敛阶至少为 α
比如说,牛顿法就是一个至少二阶收敛的方法(当不存在重根)。
下面是一个可以确定收敛阶阶数的定理:
设 p 是 g(x) 的一个不动点,若在 p 的邻域内 g(x) α≥2 阶连续,且满足
g′(p)=g(2)(p)=…g(α−1)(p)=0,g(α)=0
则 g(x) 的不动点迭代的收敛阶为 α。
重根
对计算机来说,解 x2=0 远比 x2−4x+3=0 困难。这是因为,前者要考虑重根,而且对于计算机来说,这实际上是在求 x2=±ϵ,当 ϵ<0,会出现未定义的情况。所以说,解方程有可能是不稳定的。这里的一种处理方法是,改而求解 (x2−0)2=0。
前面我们提到,对于牛顿法而言,重根的存在会导致它的收敛阶低于 2。不过,我们可以做一个修正,也就是构造另一个函数,使得它的根和原函数的根相同,但是在原重根的邻域内不存在重根。
u(x)xn+1=f′(x)f(x)=xn−u′(xn)u(xn)
关于邻域内不存在重根这一点,可以通过把函数 f(x) 写成
f(x)=(x−p)kϕ(x),ϕ(p)=0
来得出。
Aitken’s Δ² Method
对于一个一阶收敛的迭代序列,有
pn−ppn+1−p≈pn+1−ppn+2−p
据此,我们可以解出 p 的一个近似解
p≈pn+2−2pn+1+pnpn+2pn−pn+12=pn−pn+2−2pn+1+pn(pn+1−pn)2
如果引入差分的话,就可以写成
p≈pn−Δ2pn(Δpn)2
于是,我们在使用一阶收敛的方法时,就可以使用 Aitken’s Δ² Method 来加速收敛。
有人可能会考虑把 Aitken’s Δ² Method 加速完的结果再作为新的迭代起点,然而这样破坏了 linear convergence 的条件,是不可取的。
作业-3-1
P86-T11
不动点迭代方法
pn+1=g(pn)=pn−f′(pn)f(pn)−2f′(pn)f′′(pn)[f′(pn)f(pn)]2
拥有性质
g′(p)=g′′(p)=0
这会得到立方收敛的结果。比较一下平方收敛和立方收敛。
设另一个平方收敛的序列为 {qn},为了便于分析,我们设它们都收敛到 0(其实就是移动坐标轴),且
pn3pn+1≈0.5andqn2qn+1≈0.5
可以得出
∣qn−0∣∣pn−0∣≈(0.5)2n−1∣q0∣2n≈(0.5)23n−1∣p0∣3n
求解线性方程组 Linear Systems
高斯消元法
回忆在线性代数中我们的做法,使用高斯消元,把矩阵化成上三角的形式,然后一个一个解出解并回代。
我们可以用一个迭代的思路来理解:我们先把最左列除了第一行的元素清零,然后,根据高斯消元法,我们就不再会对第一行、第一列操作了。这时,我们可以忽略它们,这就相当于是再去解一个新的、阶数减一的线性方程组了。迭代进行到阶数为 1 的时候,解就出来了。
消元阶段的乘除法的数量为
k=1∑n−1(n−k)(n−k−2)=3n3+2n2−65n
进行第 k 次迭代时,需要对 n−k 行做消去操作,每一行需要操作的元素有 n−k+2 个。进行 n−1 次操作后,矩阵阶数变为 1。
回代阶段的乘除法数量为
1+i=1∑n−1(i+1)=2n2+2n
考虑第 i 次回代需要 1 次除法和 i 次乘法即可。
作业-3-2
P357-T8

Algorithm 6.1


大致步骤一致,只是在 Step4 部分有所区别:我们需要对 j=1,…n,j=i 操作。然后,我们在 Step8 阶段就可以返回所有的解:
xi=ai,n+1/ai,i,i=1,2,…,n
P358-T11

根据上一题,我们可以得出,加减法的次数为
i=1∑n(n−k+1)(n−1)=2n3−2n
乘除法的次数为
i=1∑n(n−k+2)(n−1)+n=2n3+n2−2n
为了便于计算,我们可以都只对乘除法的次数进行比较。高斯消元法需要的乘除法总数
3n3+n2−3n
故有
| n | 高斯消元法 (GE) | 高斯–约当法 (GJ) |
|---|
| 3 | 17 | 21 |
| 10 | 430 | 595 |
| 50 | 44150 | 64975 |
| 100 | 343300 | 509950 |
主元法 Pivoting Strategies
Partial pivoting/maximal column pivoting
第 i 次迭代时, 选择第 i 列中最小的 p>i,使得 ∣api∣ 是最大的。然后把第 p 行和第 i 行交换。这样可以保证除的时候除以一个较大的数。
然而,这个方法有一个问题,即除数大无法保证伸缩系数小。
时间复杂度: O(n2)
Scaled Partial Pivoting/scaled-column pivoting
不仅仅看 ∣api∣,也考虑本行中的表现。
我们定义一个 scale factor sp=max∣apj∣。这表现了这一行中的伸缩系数分子中的最大值。
然后,我们寻找第 i 列中最小的 p>i,使得 ∣spapi∣ 是最大(即最大的伸缩系数最小)的,然后交换。
但是,这么做也有个问题:每一次高斯消元的递归过程中,后面的每一行都发生了变化。如果我们每一行都这么做,会导致速度很慢。因此,注意 partial 这个词,我们的伸缩系数只在一开始计算,后面都不重新计算了。
时间复杂度: O(n2)
Complete Pivoting/maximal pivoting
一个想法是,如果在 Scaled Partial Pivoting 中每次递归过程都重新计算 sp,那么时间复杂度会到达立方。既然如此,不如也对列做交换。
对于 n 阶的线性方程组,在第 i 次递归时,会有一个 n+1−i 阶子阵。在这个子阵中,找到最大的元素 apq,然后交换 i 行与 p 行,再交换 i 列与 q 列。
时间复杂度: O(3n3)
矩阵分解 Matrix Factorization
让我们考虑每一次消元的等价操作:
令 mi1=a11ai1(a11=0),则有第一次消元等价于将原系数矩阵左乘矩阵 L1:
L1=1−m2,1⋮−mn,11⋮⋱1
依次类推,第 i 次消元等价于左乘 Li:
Li=1⋱1−mi+1,i⋮−mn,i1⋱1
既然如此,我们可以把每一个消元操作对应的矩阵先相乘。这样,可以得到一个下三角矩阵。
L=Ln−1Ln−2…L1
单位下三角矩阵乘与取逆都有封闭性。
这个下三角矩阵只与系数矩阵有关。因此,当系数矩阵一定时,这个方法效率很高。
现在,让我们重新整理一下符号。忘掉上面的 L,改取
L=L1−1L2−2…Ln−1−1
则有
A=LU,U为高斯消元法后得到的系数矩阵
可以看到,我们把 A 分解成了一个下三角矩阵 L 和一个上三角矩阵 U 的乘积。
如果我们在度量上做限制,让 L 为一个单位下三角矩阵,那么这样的分解就是唯一的。
特殊矩阵 Special Types of Matrices
- 严格对角占优矩阵 Strictly Diagonally Dominant Matrix:每一行中,对角线元素绝对值大于本行其它元素的绝对值之和。严格对角占优矩阵是非奇异 nonsingular 的。且执行高斯消元法时不需要置换行或列,其解在舍入误差上是稳定的。
直觉上,严格对角占优矩阵类似于单位阵。因此,它会有比较好的性质。
-
正定矩阵 Positive Definite Matrix:对 ∀x=0,x−1Ax>0 且 A 是对称 symmetric 的.
- 如果一个矩阵是正定的, 那么它的逆也是正定的.
- 正定矩阵的对角线元素严格大于 0.
当给了矩阵的特殊性质,我们就可以针对性质给出特定的优化算法。
正定矩阵的优化算法
当 A 是正定矩阵时,显然,它可以分解成 BΛBT 的形式,其中 B 为单位下三角矩阵, Λ 为对角线元素均大于零的对角阵。另外,我们还有
U=ΛU~
其中 Λ 是以 uii 为对角元素的对角阵,而 U~ 则因此变成了一个单位上三角矩阵。注意到 L 为一个单位下三角矩阵,则只能有 L=U~T
又因为 Λ 对角线元素均大于零,因此它可以被分解为 Λ21Λ21。那么,我们进行再整理,则有
A=L~L~T,L~=LΛ21
使用 Choleski’s Method,可以快速地计算出 L~,从而完成线性方程组的求解。

三对角矩阵的优化算法
Thomas 算法:

需要注意的是,一旦 ∃αi=0,则 Thomas 算法失效(但不意味着这个方程不可解)。
当 A 是三对角矩阵,且它是 diagonally dominant 的(注意没有要求严格),且
∣b1∣>∣c1∣>0,∣bn∣>∣an∣>0,ai=0,ci=0
则 A 非奇异,此时方程可用 Thomas 算法求解。
当 A 是三对角矩阵且严格对角占优时,方程一定可用 Thomas 算法求解。
上述两种情况下,Thomas 算法是稳定的,因为所有的中间值会受主对角线元素的约束。
Thomas 算法的时间复杂度为 O(n)。
该算法的具体实现见作业题。
Homework-1
P397-T7

a)
我们采用一个递归的思路来解释 LU 分解:
- 在已知 L 的前 i−1 列, U 的前 i−1 行的情况下,求出 U 的第 i 行
- 在已知 L 的前 i−1 列, U 的前 i 行的情况下,求出 L 的第 i 列
只要可以解决这两个递归,就能够完成 LU 分解。
对于递归(1),有(注意 lii=1 ):
j=1∑ilijujk=aik⇒uik=aik−j=1∑i−1lijujk,i≤k≤n
这里引入了 (i−1)(n+1−i) 次乘除法与 (i−1)(n+1−i) 次加减法。
对于递归(2),有:
j=1∑ilkjuji=aki⇒lki=uiiaki−∑j=1i−1lkjuji,i<k≤n
这里引入了 i(n−i) 次乘除法与 (i−1)(n−i) 次加减法。
从 i=1 一直递归到 i=n,就可以完成 LU 分解了。
乘除法数为
i=1∑n(i−1)(n+1−i)+i(n−i)=i=1∑n−32Δ(i3)+(n+2)Δ(i2)−(2n+37)Δ(i)=31n3−31n
加减法数为
i=1∑n(i−1)(2n+1−i)=i=1∑n(i−1)(n+1−i)+i(n−i)−i=1∑n(n−i)=31n3−21n2+61n
b)
考虑 y 的前 i−1 位已被求解,欲求解第 i 位,有
k=1∑ilikyk=bi⇒yi=bi−k=1∑i−1likyk
这里引入了 i−1 次乘除法和 i−1 次加减法。
于是乘除法与加减法数都为
i=1∑n(i−1)=2n(n−1)
c)
与 (b) 中相反, Ux=y 的求解是从下往上的,且因为 uii 可能不为 1,导致每一次都需要多进行一次除法,因此会每次引入 i 次乘除法和 i−1 次加减法
于是乘法数为
2n(n+1)
加减法数为
2n(n−1)
通过求和,可以解得总共需要的乘除法数量为
31n3+n2−31n
加减法数量为
31n3+21n2−65n
这与高斯消元法需要的次数相同。
d)
乘除法总数为
31n3−31n+mn2
加减法总数为
31n3−21n2+61n+mn2−mn=31n3+(m−21)n2+(61−m)n
这个小题主要体现多次求解同个系数矩阵的线性方程组时 LU 分解法的高效性。
Thomas 算法具体实现:
套用上面的 LU 分解方法(虽然不是 ppt 中的 Crout 分解),可以发现 LU 分解的递归公式变得相当简单:
uiiuii+1liili+1i=aii−lii−1ai−1i=aii+1=1=uiiai+1i
之后,我们再分别求解 y,x 的递推式,有:
yi+1xi−1=bi+1−uiiai+1iyi=ui−1i−1yi−1−ai−1ixi
注意到 l 和 u 的互相转换非常简单。因此,如果我们激进一些,完全可以只维护一个一维数组。我们记 ti=uii,则有:
ti+1yi+1xi−1=ai+1i+1−tiai+1iaii+1=bi+1−tiai+1iyi=ti−1yi−1−ai−1ixi
Read the proofs on P401-402
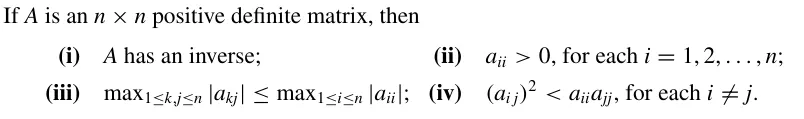
(i) 考虑 Ax=0,则有 xTAx=0。根据正定性,有 x=0。因此,Ax=0 只存在零解,故矩阵满秩,行列式不为零,是可逆的。
(ii) 这由正定性是显然的,我们只要取 xi 的第 i 位为 1,其它位为零,然后用 xTAx>0 的条件代入就可知, A 的对角线元素必然严格大于零。
(iii) 我们同样采用构造的方法。我们任意取 i,j,使得 xi=1,xj=−1,且 x 的其它位为 0。那么,有(采用爱因斯坦求和约定):
xTAx=xpApqxq=Aii+Ajj−2Aij
不妨设 Aii≥Ajj,则有
2Aii−2Aij≥Aii+Ajj−2Aij>0⇒Aii>Aij
同理,我们把 xj 改成 1,就能得到 Aii>−Aij。
综上,对于任意的 j,均存在 i=j 使得 Aii>∣Aij∣,证毕。
(iv) 令 xi=t,xj=1,i=j,其余位为 0,则有
Aiit2+2Aijt+Ajj>0
左式作为一个一元二次方程,它的 Δ 应当小于零,即
4aij2−4aiiajj<0
化简即为所求。
P412-T17
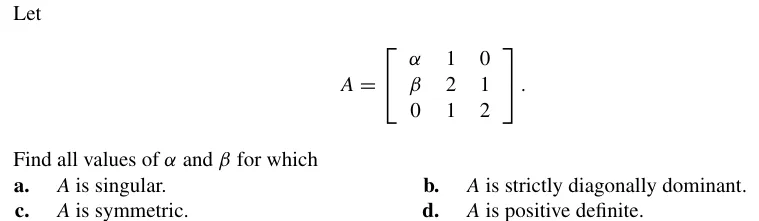
(a) 只要计算行列式为 0 即可。
∣A∣=−α+2(2α−β)=0⇒∀3α=2β 均可
(b) ∀∣α∣>1,∣β∣<1 即可
(c) ∀α;β=1
(d) 只需所有主子矩阵的行列式均为正。于是有:
α>02α−β>03α−2β>0
得 β<23α∧α>0。
矩阵代数中的迭代方法 Iterative Techniques in Matrix Algebra
我们把 Ax=b 转换成迭代形式 x=Tx+c。为了能够迭代,我们先需要进行数学上的定义。
向量的范数
我们定义向量的范数 norm。范数需要满足:
(1) 非负性 positive definite:(2) 齐次性 homogeneous:(3) 三角不等式 triangle inequality:∥x∥≥0且∥x∥=0⟺x=0,∥αx∥=∣α∣∥x∥,∀α∈R,∥x+y∥≤∥x∥+∥y∥,∀x,y.
∥x∥p=(i=1∑n∣xi∣p)p1
∥x∥∞=1≤i≤nmax∣xi∣
欧几里得范数就是二阶范数。
对于某一个范数定义, 如果一个迭代序列 xk 满足 ∥xk−x∥ 收敛于 0, 则说 xk 收敛到 x.
在有限维实向量空间中,不同范数之间总是“等价”的。也就是说,对于任意两个范数 ∥⋅∥a 和 ∥⋅∥b,存在正的常数 c 和 C,使得对所有 x 都有
c∥x∥a≤∥x∥b≤C∥x∥a.
这说明:
- 如果一个迭代序列在范数 ∥⋅∥a 下收敛,那么在任意其他范数 ∥⋅∥b 下也收敛;
- 收敛的快慢(误差量级)在不同范数下最多相差一个常数因子,不影响“收敛阶”的讨论。
因此,在数值算法和迭代方法中,我们通常只选用一种范数来分析误差,而不必担心选哪一种范数会改变收敛性质。
矩阵的范数
一般而言,前面提到的性质对于范数已经足够了。然而,为了便于分析,我们往往要求矩阵的范数还满足如下条件:
一致性 consistent:∥AB∥≤∥A∥⋅∥B∥
如果没有一致性,我们对简单的 AB 的误差分析都会变得很复杂,因为没办法从 ∥AΔB∥ 到 ∥A∥∥ΔB∥ 了。
下面也介绍常见的范数:
∥A∥F=i=1∑mj=1∑naij2
∥A∥p=x=0max∥x∥p∥Ax∥p=∥x∥=1max∥Ax∥p
这个依赖于向量的定义似乎有些奇怪,但其实它表现了空间各个方向上矩阵算子最强的拉伸能力。
常用的自然范数有:
∥A∥∞∥A∥∞∥A∥2=1≤i≤nmaxj=1∑n∣aij∣=1≤j≤nmaxi=1∑n∣aij∣=λmax(ATA)(谱范数)
无穷自然范数的证明:
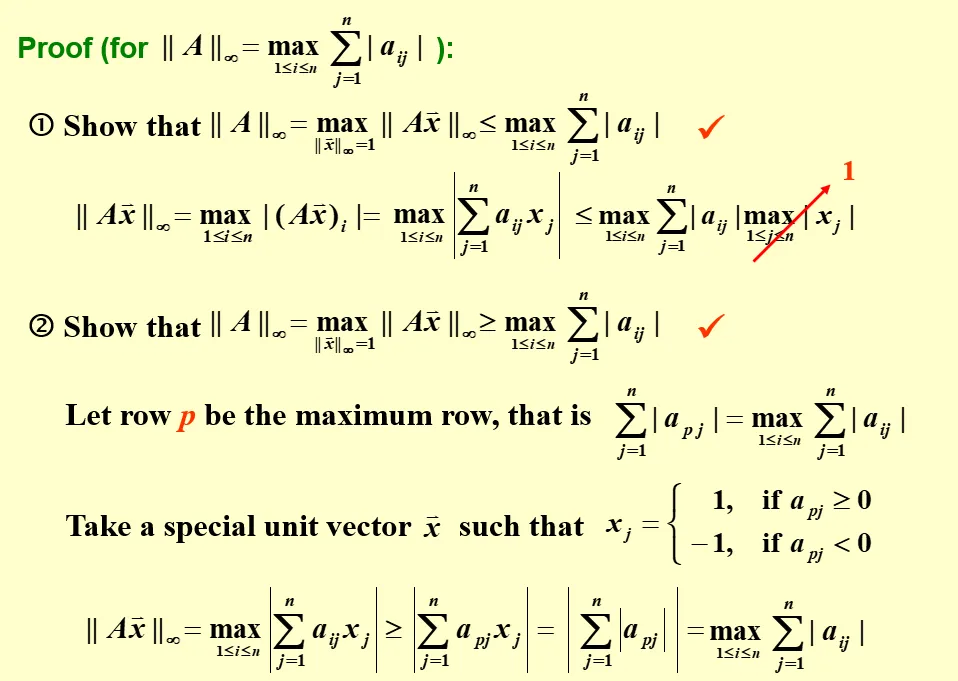
特征值与特征向量 Eigenvalues and Eigenvectors
谱半径 Spectral Radius
对于矩阵 A ,其特征值可能是复数。因此,我们利用复数的幅值来刻画它们,其中最大的幅值也就是谱半径 ρ(A) 。
对于一个 n 阶矩阵,对于任意的自然范数,有 ρ(A)≤∥A∥
Prove:
∀ eigenvalue λ,∣λ∣⋅∥x∥=∥λx∥=∥Ax∥≤∥A∥⋅∥x∥
如果一个 n 阶矩阵满足对于任何 i,j=1,2,…,n,有 limk→∞(Ak)ij=0,则说这个矩阵是收敛的。
雅可比迭代法 Jacobi Iterative Method
雅可比迭代法的思路是构造一个便于求解的迭代式(系数矩阵只是个对角阵),以提高迭代效率。
我们把一个矩阵 A 分成对角阵 D 与上三角阵 −U 和下三角阵 −L 的和,则有
Ax=b⟺Dx=(L+U)x+b
这就出现了一个可迭代式(假设 D 可逆)
x=D−1(L+U)x+D−1b
我们定义雅可比迭代法的系数 Tj=D−1(L+U),cj=D−1b,则有迭代式
x(k)=Tjx(k−1)+cj
具体算法:
首先,我们合适地交换行或列,使得对于 i=1,…,n, aii=0。
然后,根据迭代式,每一次迭代,我们从 i=1 直到 n,计算
xi(k+1)=aiibi−∑j=i&j=1naijxj(k)
在这里,我们需要使用两个向量来维护 x(k),x(k+1)。当不使用并行优化时,这么做显得有些浪费。一个想法是,我们始终只维护一个向量 x ,此时,在计算 xi 时,是使用了新的 1…i−1 个分量和其它旧的分量。这也就引出了高斯-赛德尔迭代法。
高斯-赛德尔迭代法 Gauss-Seidel Iterative Method
在直觉上,对于将 A 分裂,然后一部分放到方程右边构造的迭代法,扔到方程右边的部分越多,收敛得就越快。
这通过极限思想容易想通,把 A 拆成 A 和 0 后,一次迭代就收敛了。
当然,我们还需要保证迭代式易于求解的问题,因此一些拥有优良性质的矩阵就适合被留下来,把剩余部分扔到迭代右式里。
Gauss-Seidel Iterative Method 的思路就是解一个系数矩阵为下三角矩阵的迭代式。我们做如下拆分:
(D−L)x=Ux+b⟺x=(D−L)−1Ux+(D−L)−1b
类似地,我们定义 Tg=(D−L)−1U,cg=(D−L)−1b,则有迭代式
x(k)=Tgx(k−1)+cg
在具体实现上,很巧的是,这恰恰是我们在尝试对雅可比迭代法的空间占用上做优化的结果。
对于不同的问题,Jacobi 和 Gauss-Seidel 迭代法有不同的表现。有时前者好用后者不好用,反之的情况也会存在。但至少让我们关注一下收敛性的问题吧。
迭代方法的收敛性
首先介绍如下定理:
对于矩阵 A,下面五个命题等价:
- A 是收敛的。
- 对于某个自然范数,有 limn→∞∥A∥=0
- 对于任意自然范数,有 limn→∞∥A∥=0
- ρ(A)<1
- 对于任意的 x,有 limn→∞Anx=0
拥有如上定理之后,我们可以得出一个结论:
对于任意的迭代式
x(k)=Tx(k−1)+c
只要满足 ρ(T)<1,迭代式就必然收敛到解
x=Tx+c
Proof:
我们将迭代式展开,则有
x(k)=Tkx(0)+(Tk−1+…+T+I)c
由于 ρ(T)<1,有对于任意的 x, limn→∞Tnx=0。因此,当我们取 k 无限大时,就有 Tkx0→0。
于是,我们有
k→∞limx(k)=(I−T)−1c
而这恰好就是 x=Tx+c 的解。
回忆前文,我们知道,对于任意的自然范数 ∥⋅∥,有 ρ(T)≤∥T∥。这说明, ∥T∥<1 是比 ρ(T)<1 更强的条件。当满足这个更强的条件时,有如下结论:
迭代式
x(k)=Tx(k−1)+c(given ∀ natural norm∥T∥<1)
收敛,且其中间解与收敛终点的误差控制在:
x−x(k)x−x(k)≤∥T∥kx−x(0)≤1−∥T∥∥T∥kx(1)−x(0)
对于一个严格对角占优的矩阵 A,不管迭代起点如何选取,Jacobi 和 Gauss-Seidel 法都会得到收敛到唯一解的迭代序列。
Relaxation Methods
回忆第一个 research topic 中我最终对不动点迭代的方法,可以发现一个特殊的视角:
我们可以把不动点迭代写成
x(k+1)=x(k)+Δ(k+1)
其中 Δ(k+1) 是一个有关于 x(k) 的函数,且当 x(k) 为不动点时取值为 0。这个函数事实上表现了每一步迭代的步长。
接着这个视角,我们可以把 Gauss-Seidel 迭代法写成如下的形式:
xi(k+1)=xi(k)+aiibi−∑j<iaijxj(k+1)−∑j≥iaijxj(k)
特殊地,我们记
ri(k+1)=bi−j<i∑aijxj(k+1)−j≥i∑aijxj(k)
并称之为残差 residual。
这样,就有
xi(k+1)=xi(k)+aiiri(k+1)
回忆一下我们上面提到的视角,我们很容易想到一件事,这个迭代的步长也许可以加一些系数来调整。这也就是所谓的 relaxation method:
xi(k+1)=xi(k)+ωaiiri(k+1)
根据 ω 的范围不同,我们把 relaxation method 分为
- 0<ω<1 Under-Relaxation Methods
- ω=1 Gauss-Seidel Methods
- ω>1 Successive Over-Relaxation Methods
经过化简,我们可以得出 relaxation method 的一个不太简洁的矩阵表示:
x(k+1)=(D−ωL)−1[(1−ω)D+ωU]x(k)+(D−ωL)−1ωb=Tωx(k)+cω
下面不加证明地给出几个定理:

对于不同的方程,我们可以通过调整 ω,使得谱半径达到最小,此时收敛速度最快。
Homework
Read the proof of Theorem 7.7 on p.423
证明:对于任意 x∈Rn,有
∥x∥∞≤∥x∥x≤n∥x∥∞
不妨令 xt 是 x 的分量中绝对值最大的,则有
∥x∥∞=∣xj∣2≤i=1∑nxi2=∥x∥22
且也有
∥x∥22=i=1∑nxi2≤nxj2
综上开根即证。
P429-T5(a)
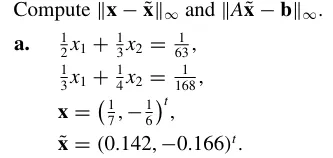
x−x~∥x−x~∥Ax~−b∥Ax~−b∥≈1×10−4(8.57,−6.67)T=8.57×10−4≈(−0.00020,−0.00012)T=2.0×10−4
P429-T7
Show by example that ∥⋅∥ defined by ∥A∥=max1≤i,j≤n∣aij∣ doesn’t define a matrix norm.
其实这里非负性,齐次性和三角不等式都是满足的,只能考虑一致性了。
令 A=(1111),则有 A2=(2222),不满足 ∥A2∥≤∥A∥2。
P430-T13
Prove that if ∥⋅∥ is a vector norm on Rn, then ∥A∥=max∥x∥=1∥Ax∥ is a matrix norm.
非负性和齐次性显然。
对于三角不等式,设 x=xi 令 ∥Ax∥ 取最大, x=xj 令 ∥Bx∥ 取最大, x=xk 令 ∥(A+B)x∥ 取最大,有
∥A+B∥=∥(A+B)xk∥≤∥Axk∥+∥Bxk∥≤∥Axi∥+∥Bxj∥=∥A∥+∥B∥
对于一致性,有
∀∥x∥=1,∥ABx∥=∥A(Bx)∥≤∥A∥∥Bx∥≤∥A∥∥B∥
即
∥AB∥≤∥A∥∥B∥
P436-T3
a.c.e.g.(2−1−12)(021210)210120003221131122b.d.f.h.(0111)(1−21−2)−1002300473122−20−134
这些矩阵中,哪些是收敛的?
本题应该就是考察谱半径的求解,也就是特征值的求解。
只以 (d), (h) 为例。
(d):
det(1−λ−21−2−λ)=λ2+λ=0
解得 λ1=0,λ2=−1,故谱半径为 1,不收敛。
(h):
det3−λ122−2−λ0−134−λ=−λ3+5λ2+2λ−24=0
解得 λ1=3,λ2=4,λ3=−2,故谱半径为 4,不收敛。
p453-T13
证明 Kahan 定理:
如果 aii=0,i=1,2,…,n,则有 ρ(Tω)≥∣ω−1∣
Proof:
Tω=(D−ωL)−1[(1−ω)D+ωU]
首先,让我们回忆一下线性代数的内容:
对于 n 阶矩阵 A,有它的特征多项式 det(λE−A) 等于
λn+b1λn−1+…+bn−1λ+bn, where bk=(−1)kSk
其中 Sk 为 A 的所有 k 阶主子式之和。
由这个定理,可以得到两个重要推论:
i=1∑nλii=1∏nλi=i=1∑naii=det(A)
而我们需要使用的是第二个。
我们可以注意到, (D−ωL)−1 是一个下三角矩阵, [(1−ω)D+ωU] 是一个上三角矩阵,而它们的行列式是非常好计算的,即为对角线元素的乘积。
对于 (D−ωL)−1,其对角线元素为 aii1;对于 [(1−ω)D+ωU],其对角线元素为 aii1−ω。于是,我们有
det(Tω)=(1−ω)n
根据平均原则,特征值最大的模至少要为 ∣1−ω∣,得证。
Error Bounds and Iterative Refinement
Condition Number 条件数
对于一个方程 A(x+δx)=b+δb,有相对误差范围
∥x∥∥δx∥≤∥A∥⋅A−1⋅∥b∥∥δb∥
∥A∥⋅A−1 表现了相对误差的放大系数,被记为 K(A),即条件数 condition number。可以看出,我们希望 K(A) 越小越好。
考虑给矩阵 A 乘以一个非零系数 λ,可以发现相对误差是不变的。这说明,如果一个方法解 Ax=b 正常,那么它解 λAλx=b 也是可行的,这体现了求解算法的不变性。
对于 K(A),有如下结论成立:
- 如果 A 是对称的,那么 K(A)2=min∣λ∣max∣λ∣。在几何上理解,我们考虑一个三维空间,对称的 A 把一个球映射成一个椭球, K(A)2 也就是最长轴与最短轴的比值。因此, K(A)2 刻画的是这个椭球的扁平程度。
- 对于任意的自然范数 ∥⋅∥p,有 K(A)p≥1
- K(λA)=K(A),考虑乘以一个缩放倍数不改变几何图形的形状。
- 对于正交矩阵 A(A−1=AT),有 K(A)2=1。正交矩阵又名旋转矩阵,可以证明它具有保范性。因此,它对应的椭球就是一个正球,自然 K(A)=1。
- 对于正交矩阵 R,有 K(RA)2=K(AR)2=K(A),理由同上。
对于一样的方程,我们假设 b 是准确的,而 A 拥有误差 δA,则有
(A+δA)(x+δx)=b
此时有结论
∥x∥∥δx∥≤1−K(A)∥A∥∥δA∥K(A)∥A∥∥δA∥
更进一步地,当 A 和 b 均存在误差时,如果我们限制 ∥δA∥<∥A−1∥1,则有
∥x∥∥δx∥≤1−K(A)∥A∥∥δA∥K(A)(∥A∥∥δA∥+∥b∥∥δb∥)
数值秩
在明确误差存在,且可以估计误差的基础上,我们可以引入方程数值可解的概念。
在数学上,我们可以通过行列式是否为 0 来判断矩阵是否满秩。如果不满秩,说明矩阵是退化的,也就没有唯一解。
而在数值分析中,我们有数值秩的概念。当数值求解出行列式的绝对值小于某个范围时,我们就认为这个矩阵在数值秩意义上是不满秩的,因而是不可解的。这里的不可解体现在 K(A) 非常大,因此误差极大,数值解不可信(考虑 ∣A∣=λ1λ2…λn, ∣A∣≈0 时, λamax 极有可能非常接近 0,从而导致 K(A) 非常大)。
Iterative Refinement
在线性方程组的迭代求解中,我们同样引入残差向量的概念:
对于迭代过程中的某个 x(k),有其残差为
r(k)=b−Ax(k)
类似于 b 存在误差时对解的误差的估计,对于任意的自然范数,我们有
∥x∥x−x(k)≤K(A)∥b∥r(k)
这也等价于
x−x(k)≤r(k)⋅A−1
据此,我们只需要控制 r(k)⋅A−1 收敛即可。
一种被称为 Iterative Refinement 的迭代方法如下:
设 d(k)=A−1r(k),由于矩阵求逆需要计算较多,因此我们使用求解线性方程组 Ad(k)=r(k) 的方式求解 d(k)。
我们可以构造下面的迭代步骤:
- 求解 Ax(k)=b
- 计算 r(k)=b−Ax(k)
- 求解 Ad(k)=r(k) 得到 d(k)
- 取 x(k+1)=x(k)+d(k)
每一步中,我们可以得到一个残差,利用残差可以得到大概 x 还需要变多少才能变得准确,这个“多少”也就是 d(k)。每一步中,我们都利用残差估计 x(k) 应该怎么变,从而得到 x(k+1),这就是上述迭代方法的思路。
然而,这个方法在实际实践中比较少使用,主要的原因是一些情况下它不会收敛。
补充
若对于某个自然范数,矩阵 B 满足 ∥B∥<1,则有 I±B 非奇异,且
(I±B)−1≤1−∥B∥1
Homework-week7-1
首先,回忆二阶矩阵的求逆公式:
对于二阶矩阵 A=(acbd),其逆为
A−1=∣A∣(d−c−ba)
于是易解。
对于更高阶的矩阵,回想一下伴随矩阵 A∗,它满足 aij∗ 为 aji 的代数余子式。另一种表达,则是伴随矩阵为原矩阵的代数余子式矩阵的转置。对于矩阵的逆,有
A−1=∣A∣A∗
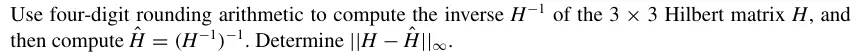
回忆希尔伯特矩阵 H 的定义:
hij=i+j−11
因此,三阶希尔伯特矩阵为
12131213141314151
后面易解。
这题的用意是比较两次取逆后的数值解和原本的希尔伯特矩阵之间的误差。希尔伯特矩阵的条件数是随着矩阵维度的增加迅速增大的,它是数值分析中一个典型的病态矩阵。
Approximating Eigenvalues
在本章中,我们讨论如何求解一个矩阵的主特征值 dominant eigenvalue,即拥有最大绝对值的特征值。
Power method
设 A 为 n×n 的矩阵,且满足特征值 ∣λ1∣>∣λ2∣≥∣λ3∣…≥∣λn∣≥0。此时,有 n 个线性无关的特征向量 xi,i=1…n 。
我们考虑把任意的向量 x 用上述的特征向量分解,并不断地用 A 去乘 x。最终, Akx 会趋向于 λ1kαx1,其中 αx1 为 x 在 x1 上的分量(考虑 ∣λ1∣ 严格大于 ∣λ2∣,因此其它分量会等比收敛)。
在有了 Akx→λ1kαx1 的认识的基础上,我们也很容易想到,用
λ1≈x(k)x(k+1),x(k)=A(k)x
的方式来估计 λ1,并通过每次迭代中估计值的变化量来决定是否停止迭代。
当然,这样的方法存在问题,那就是你无法保证计算的稳定性。考虑 ∣λ1∣<1 的情况,随着迭代的进行, ∥x(k)∥ 会逐渐趋于零,导致计算误差增大。因此,一个朴素的想法是,让每一次迭代后都做一次标准化,保证 ∥x(k)∥ 在一个合适的范围。
Normalization
在每一次迭代过程中,我们保证 x(k)=1。我们只需这么操作:
- 令标准化后的 u(k) 为 x(k) 除以其无穷范数后的结果
- 令迭代式为 x(k+1)=Au(k)
- 记 dominant index i(k) 为 x(k) 中决定无穷范数的分量对应的 index,则第 k+1 次迭代时, λ1 的估计为 x(k+1) 的第 i(k) 位。这是因为,在第 k 次迭代中,我们把 x(k) 的第 i(k) 个分量标准化为了 1,它在下一次迭代中的变化就体现了 λ1 的伸缩效果。
- 在迭代过程中,需要注意 x(0) 的选取。如果恰好选中了特征值 0 的特征向量,那么就应该重新选取 x(0)
- 该迭代法也适用于 λ1=λ2…=λi 的情况,但是不适用于 λ1=−λ2 的情况。
- 如果 x(0) 完全没有 x1 方向上的分量,那么求得的就不是 λ1,而是对应的特征向量上分量不为零的、绝对值最大的特征值。
- 该方法的收敛速度由 λ1λ2 决定,是线性收敛的,因此可以使用 Aitken’s Δ2 Acceleration,其中的迭代序列需要取 x(k)[i(k−1)]。
Inverse Power Method
在 Normalization 的讨论中,我们提到, Power Method 的收敛速度由 λ1λ2 决定。那么,一个自然的想法,就是让这个比值尽可能的小。
如果我们考虑使用对 λi 所在的一维坐标系平移来实现这一点,最大限度地提升 λ2λ1 的办法是,让新的坐标原点为旧系中的 2λ2+λn,即构造一个新的矩阵,使得所有的特征值都减去 p=2λ2+λn。
这种新的矩阵可以简单地通过 B=A−pI 来构造。此时,有
λ2−pλ1−p>λ2λ1
即收敛加速。
这时,我们需要求解 λn。考虑对 A−1 做迭代,那么我们将解出其 dominant eigenvalue 为 λn1。
需要注意的是,由于计算矩阵的逆较为麻烦,我们实际上在每一次迭代中用
Ax′(k+1)=x′(k)
的方式解出 x′(k+1)。
你可能发现了,其实我们只要提升收敛速度就好, p 的取值只要有道理就好了。因此,我们也可以选择求解一些虽然不能最大限度提升收敛速度,但是求解上比较方便的 p,并据此提升收敛速度。
另外,取 p=2λ2+λn 时,迭代并不能无限地加速。随着迭代速度越来越快,可以发现,求解线性方程组时对应的条件数也越来越大,这两者存在着相互的制约。
插值与多项式近似 Interpolation and Polynomial Approximation
当一个函数非常难以计算,有一种方法是,用已知的点来估计未知的点。这样,就自然地出现了一个用采样点来求解未知点的函数。这样的函数就叫做插值函数(Interpolation function)。为了便于计算,最流行的插值函数是个多项式。
Pn(x)=a0+a1x+…+anxn
我们把采样点代入,要求这个函数满足采样点对应的函数关系。这就相当于一个待定系数法。
拉格朗日插值 Interpolation and the Lagrange Polynomial
拉格朗日插值 Pn 是由多个拉格朗日基函数(basis function) Ln,i 组合而成的。
对于 n+1 个点 (xi,yi),有
Pn(x)=i=0∑nLn,i(x)yi
而每一个基函数的表达式为
Ln,i=j=i,j=0∏n(x−xj)⋅j=i∏xi−xj1
对于给定的点,拉格朗日插值是唯一的。
Remainder
我们走进了近似函数这一步,自然也要有对函数近似的误差。对于一个函数 f 和与之对应的插值函数 P,我们有误差函数
R(x)=f(x)−P(x)
如果我们对 f 在 [a,b] 中的 n+1 个 x0≤x1…≤xn 取拉格朗日插值 Pn ,且 f(x)∈Cn+1[a,b],则有
Rn(x)=f(x)−Pn(x)
显然地, Rn 拥有 n+1 个根,于是我们一定能把它写成
Rn(x)=K(x)i=0∏n(x−xi)
问题是, K(x) 是什么呢?我们总是希望能够确定 K(x) 的范围,从而确定 Rn(x) 的范围。
注意到,我们需要求的是 K(x),而对于 Rn(x),它在 [a,b] 上有 n+1 个根的性质是明朗的,而 ∏i=0n(x−xi) 的性质也是非常好的,只有欲求的 K(x) 的性质是模糊的。如果我们希望利用这些仅有的性质来尝试着表达 K(x) 可能的性质,一个好的思路就是把 K(x) 和 Rn(x),∏i=0n(x−xi) 拆分开来。
这里,我们采用换一个元的方式做拆分:
对于任意的 x=xi,我们暂时先把它固定住,然后引入一个新的变量 t。当 t=x 时,就会有
Rn(t)=K(x)i=0∏n(t−xi)
这时,我们不难发现,这个发生了变量替换之后产生的方程,总共拥有 n+2 个解。换而言之,如果我们定义
g(t)=Rn(t)−K(x)i=0∏n(t−xi)=f(t)−Pn(t)−K(x)i=0∏n(t−xi)
那么 g(t) 会拥有 n+2 个根。
根据罗尔中值定理,我们可以在 [a,b] 上找到某个点 ξ ,使得 g(ξ)(n+1)=0。此时,有
f(n+1)(ξ)−K(x)⋅(n+1)!=0
即得
K(x)=(n+1)!f(n+1)(ξ)
综上有
Rn(x)=(n+1)!f(n+1)(ξ)i=0∏n(x−xi)
在直观方面,我们取 p(x)=∏i=0n(x−xi),这可以看成一个基础的单位插值多项式。
那么,我们就可以把 Rn(x) 表示成
Rn(x)=p(n+1)(ξ)f(n+1)(ξ)p(x)
这很好地显示了 Rn(x) 的几何含义:我们把原函数的更高阶导数和单位插值多项式的更高阶导数做一个比值,这就衡量了误差的系数。然后,再乘以单位插值多项式来表示插值位置对应的误差。
自然地,对于一个多项式,只要插值次数足够,那么它就一定是准确的了。
Neville’s Method
k 阶的拉格朗日插值多项式之间存在着递推的关系,这表现为:
设一个函数 f 有解 x0,x1…xk,则它的 k 阶拉格朗日插值多项式可以用两个 k−1 阶插值多项式来表示:
P(x)=xi−xj(x−xj)P0,1,…,j−1,j+1,…k(x)−(x−xi)P0,1,…,i−1,i+1,…k(x)
或者表达成这种形式:
P(x)=xi−xjx−xjP0,1,…,j−1,j+1,…k(x)+xi−xjxi−xP0,1,…,i−1,i+1,…k(x)
其中要求 i=j。
第二种形式自然地对应了加权和的理解。对于缺少了 xj 的插值,它在 xj 处的误差在直觉上较大,因此,我们不希望它影响更高一阶的插值。于是,我们就把 xi−xj 中的 xi 替换成 x,使得这个插值在 xj 处的权重为 0。另一个插值也是同理。
Neville’s Method 就是一个利用这种递推关系来求解高阶拉格朗日插值多项式的方法。
我们不妨简记 P0,1,…,k(x)=N0,k,那么就能发现这样一件事情:
Ni,j+1=xi−xj+1x−xj+1Ni,j+xi−xj+1xi−xNi+1,j+1
这足以让我们建立一个合适的递推方法。
我们不妨用一个二维坐标来描述求解 N0,k 的思路。把 Ni,j 映射为坐标 (i,j),则有:
- 初值为线段 y=x 上的点 (0,0),(1,1),…,(k,k)
- 将 y=x 上相邻的点做递推,可以得到 (0,1),(1,2),…,(k−1,k),也即线段 y=x+1
- 如此一直递推,我们可以得到 y=x+2,…,y=x+k
- 线段 y=x+k 其实就是 (0,k),也就是 N0,k,求解完毕。
所以,如果在几何直观上思考,Neville’s Method 表现为一个 45° 线段不断平移缩短,最后变成一个点的过程。
让我们以具体题目为例:
Use Neville’s method to approximate 3 with the function f(x)=3x and the values (x0,x1,x2,x3,x4)=(−2,−1,0,1,2)
第一轮迭代: 91,31,1,3,9
第二轮迭代: 32,34,2,0
第三轮迭代: 23,611,23
第四轮迭代: 916,35
第五轮迭代: 2441≈1.7083
迭代过程还是比较麻烦的,建议的算法是:
- 把每一轮都写成一行,明确上下迭代关系
- 不要求解 x 的表达式,而是直接代入 x=21
- 优先根据 xi−xjx−xj+xi−xjxi−x=1 的关系,把每一轮迭代需要乘的系数先列出来
Newton Interpolation
牛顿插值法旨在每新增一个样本点,前面的基函数不发生改变。
对于单个取样点 x0,牛顿插值为 f0。
再加一个取样点 x1,我们希望保持前面的插值不变,因此新加的基函数 N(1)=(x−x0)。于是,牛顿插值为
f0+(x−x0)x1−x0f1−f0
依次类推,第 i+1 个基函数也就是
N(i)=j=0∏j<i(x−xj)
我们再把对应的系数记为 α(i),那么,我们求解牛顿插值的过程,其实也就是求解一个线性方程组:
111⋮10(x1−x0)(x2−x0)⋮(xn−x0)00(x2−x0)(x2−x1)⋮(xn−x0)(xn−x1)⋯⋯⋯⋱⋯000⋮∏j=0n−1(xn−xj)α(0)α(1)α(2)⋮α(n)=f(x0)f(x1)f(x2)⋮f(xn)
这时出现的是一个下三角矩阵。如果我们考虑拉格朗日插值,会发现矩阵为单位矩阵。
从另一个角度思考,其实一个多项式是它对应的线性空间中的一个点。我们选择一个插值方法,其实也就是以它定义的基函数为基,求解对应的空间坐标(系数)。拉格朗日插值中,基的选取较为复杂,但是使得方程的求解更加简单;牛顿插值中,基的选取非常自然,而方程求解则复杂一些。
当这个矩阵满秩时,事实上,对 n+1 个取样点求解的 n 阶多项式是唯一的(即通过每个取样点建立的基函数集能够构成这个 n+1 维多项式线性空间的一组基)。于是,牛顿插值和拉格朗日插值的结果本质上是等价的,误差 R(x) 也是等价的。
差分 Divied Differences
我们介绍差分作为表述牛顿插值的一种形式。
函数的一阶差分如下表示:
f[xi,xj]=xi−xjf(xi)−f(xj)(i=j,xi=xj)
且函数差分之间存在如下的递推关系:
f[x0,…,xk+1]=x0−xk+1f[x0,x1,…,xk]−f[x1,…,xk,xk+1]
经过推导,我们可以得到
f[x0,…,xk]=i=0∑k∏j=0,j=ik(xi−xj)f(xi)
这事实上在说明一件事情,也就是 f[x0,…,xk] 的取值与 x0,…,xk 的顺序是没有关系的。也正因此,上面的递推式中,其实取任意两个点之间的差都是可以的。
那么,我们就可以写出这样一个式子:
f[x,x0,…,xk+1]=x−xk+1f[x,x0,…,xk]−f[x0,…,xk+1]
通过整理,可以得到
f[x,x0,…,xk]=f[x0,…,xk+1]+f[x,x0,…,xk+1](x−xk+1)
把左侧看成一个函数,右边就可以看成添加一个取样点 xk+1 后对它的重新表示。这让我们联想到牛顿插值中不断添加取样点的过程。
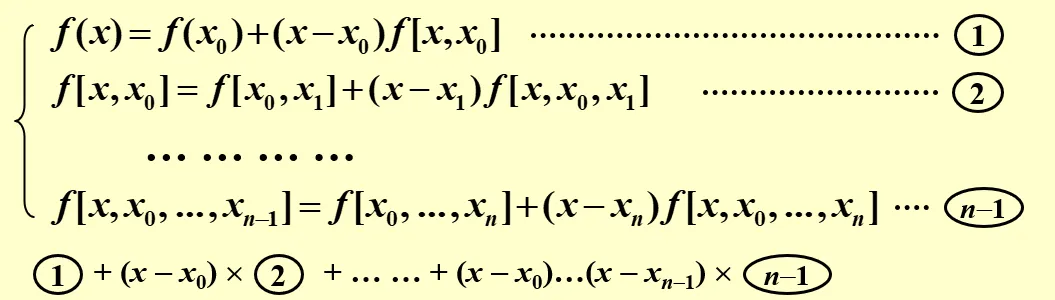
于是,对于一个函数 f(x),我们总是可以把它表示成
f(x)=f(x0)+f[x0,x1](x−x0)+…+f[x0,…,xn](x−x0)…(x−xn−1)+f[x,x0,…,xn](x−x0)…(x−xn)
其中第一行也就是牛顿插值,第二行则是牛顿插值的残差。
如果我们简记差分 f[xi,…,xj] 为 Di,j,同样可以发现有已知 Di,j,Di+1,j+1 可求解 Di,j+1 的递推关系。因此,它的递推思路和 Neville’s method 是一样的。
Di,j+1=xi−xj+1Di,j−Di+1,j+1
根据递推的方向,牛顿差分公式被分为前向差分(forward-difference formula) 和后向差分 (backward-difference formula)。
牛顿前向差分
我们令牛顿插值的采样间距 xi+1−xi=h,并假设我们需要估计的点坐标为 x=x0+th。定义前向差分为:
Δy0Δ2y0ΔyiΔkyi=y1−y0=Δy1−Δy0=yi+1−yi=Δk−1yi+1−Δk−1yi
那么,就可以得到
f(x)≈y0+tΔy0+2t(t−1)Δ2y0+…+n!t(t−1)…(t−n+1)Δny0
误差为
(n+1)!fn+1(ξ)t(t−1)…(t−n)hn+1
牛顿后向差分
同样地,我们定义后向差分为:
∇yn∇2yn∇kyn=yn−yn−1=∇yn−∇yn−1=∇k−1yn−∇k−1yn−1
并假设需要估计的点坐标为 x=xn+th,则有
f(x)≈yn+t∇yn+2t(t+1)∇2yn+…+n!t(t+1)…(t+n−1)∇nyn
误差为
(n+1)!fn+1(ξ)t(t+1)…(t+n)hn+1
符合直觉地,当待估计点与 x0 更近时,前向差分误差更好,反之亦然。
一个例子如下:
有函数满足:
f(0.0)f(0.2)f(0.4)f(0.6)f(0.8)=1.00000=1.22140=1.49182=1.82212=2.22554
我们尝试使用牛顿前向插值来估计 f(0.05)。
首先,可以得到 h=0.2,t=0.25。
接下来,我们列差分表来实现类似于 Neville 的递推:
1.000001.221401.491821.822122.225540.221400.270420.330300.403420.049020.059880.073120.010860.013240.00238
这个递推表完成了 0 到 4 阶的前向差分。最后,将对角线上的差分代入公式即可。
Hermite Interpolation
在过去的插值中,我们只是要求每一个取样点的函数值相同,而没有关注它们的导数。如果我们考虑让它们的 n 阶导数也相同,那么就能够获得更多的条件,从而也获得一些插值。
Hermite 插值就是这样的插值中的一种特例——它要求一阶导也相同。
对于取样点 x0,…,xn,我们要求 Hermite 插值 H2n+1(x) 满足 H2n+1(xi)=yi
和 H2n+1′(xi)=yi′。
我们将 Hermite 插值记作
H2n+1(x)=i=0∑nyihi(x)+i=0∑nyi′h^i(x)
因为系数解已经取了 yi 和 yi′, 对于 hi(x),除了 xi 都是它的重根(因为那里的导数也要取零)。于是,有
hi(x)=(Aix+Bi)Ln,i2(x)
通过代入条件 hi(xi)=1,hi′(xi)=0,可以解得
hi(x)=[1−2Ln,i′(xi)(x−xi)]Ln,i2(x)
通过类似的思路,可以解得
h^i(x)=(x−xi)Ln,i2(x)
Hermite 插值对应的残差为
Rn(x)=(2n+2)!f2n+2(ξ)[i=0∏n(x−xi)]2
这个形式也确实和拉格朗日插值的相似。
立方样条插值 Cubic Spline Interpolation
提升插值多项式的次数并不一定能保证得到一个更好的结果,因为高阶多项式存在着振荡的现象。
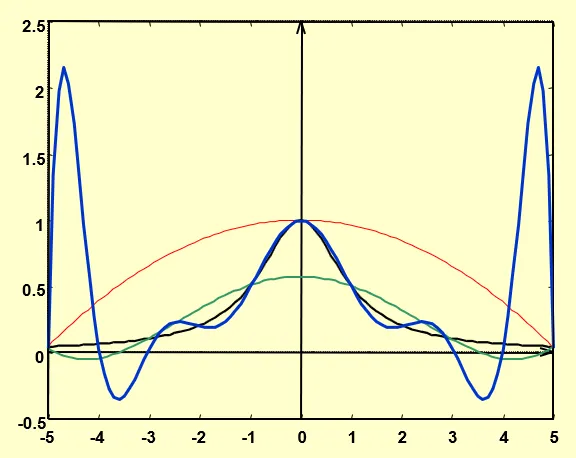
为了减小振荡,我们可以选择分段插值,即把定义域分成数个区间,在每一个区间内用单独的插值函数来插值。只要区间分得够细,那么这么多个插值组合起来的插值函数就越接近原函数。
然而,这么做可能有个问题:如果我们随意地取分段插值函数,那么每一个分段的点上,总的插值函数可能是不连续的。
为了保证连续这一点,一个自然的思路是使相邻的两个分段插值函数在分界点上的导数相同。
在现实世界中,往往需要一阶导的连续是不够的。考虑开火车,我们不仅希望速度(一阶导)是连续的,还希望加速度(二阶导)是连续的,否则力就会发生突变,那样就比较糟糕。因此,我们还要求分界点的二阶导同样相同。为了使这一点有意义,每一个分段插值都至少应该是个三阶多项式。
Method of Bending Moment
Method of Bending Moment 是用于求解 Cubic Spline Interpoloation 的一种方法。
我们记以 x0,x1,…,xn 为采样点的立方样条插值为 S(x),且在 [xj−1,xj] 上的分段插值为 Sj(x),区间长度 xj−xj−1 为 hj。然后,我们简记
Mj−1=Sj′′(xj−1),Mj=Sj′′(xj)
根据立方样条插值的条件,我们有
Sj′′(Xj−1)′=Sj−1′′(xj−1)
可以发现左右两侧都会被简记成 Mj−1。因此,这个记法是合理的。
在每一个分段 [xj−1,xj] 中,我们首先考虑 Sj′′(x),它对应着由 (xj−1,Mj−1) 与 (xj,Mj) 决定的线性插值。于是有
Sj′′(x)=Mj−1hjxj−x+Mjhjx−xj−1
通过把它积分两次,我们可以得到两个含待定系数的方程:
Sj′(x)Sj(x)=−Mj−12hj(xj−x)2+Mj2hj(x−xj−1)2+Aj=Mj−16hj(xj−x)3+Mj6hj(x−xj−1)3+Ajx+Bj
如果我们希望通过 Mj,Mj−1 表示出 Aj,Bj,那么结合
Sj(xj−1)Sj(xj)=yj−1=yj
两个条件,我们可以构造出二元一次方程组,并求解出
AjBj=hjyj−yj−1−6Mj−Mj−1hj=f[xj−1,xj]−6Mj−Mj−1hj=hj1(xjyj−1−xj−1yj)+6hj(Mjxj−1−Mj−1xj)
然后,根据 S′(x) 在 xj 处连续,我们有
Sj′(xj)Sj+1′(xj)=f[xj−1,xj]+6hj(2Mj+Mj−1)=f[xj,xj+1]+6hj+1(2Mj+Mj+1)
且 Sj′(xj)=Sj+1′(xj)
于是,我们可以构造出含三个未知数 Mj−1,Mj,Mj+1 的方程
μjMj−1+2Mj+λjMj+1=gj
其中
λjμjgj=hj+hj+1hj+1=1−λj=hj+hj+16(f[xj,xj+1]−f[xj−1,xj])
且 1≤j≤n−1
现在,我们有 n+1 个未知数 M0,…,Mn,同时有 n−1 个方程。我们还需要加上两个方程才能够求解这个线性方程组。这两个方程对应着 x0,xn 上特殊的边界条件。
Clamped boundary
Clamped boundary 分别提供了两个边界的导数值 y0′,yn′,并要求 S1′(x0),Sn′(xn) 对应相等。此时,我们定义一个无限接近于 x0 的取样点 x−1,那么就有
λ0μ0g0=h0+h1h1=h1h1=1=1−1=0=h0+h16(f[x0,x1]−f[x−1,x0])=h16(f[x0,x1]−y0′)
于是有
2M0+M1=g0
同理,我们也可以构造出
λnμngnMn−1+2Mn=0=1=hn6(yn′−f[xn−1,xn])=gn
Free boundary/Natural Spline
我们也可以不对边界的导数值作约束,而是对边界的二阶导做约束。我们提供两个边界的二阶导 y0′′,yn′′,并要求 S1′′(x0),Sn′′(xn) 对应相等。
这时,我们就直接多了两个方程
M0Mn=y0′′=yn′′
于是方程组也可解了。
特殊地,当 y0′′=yn′′=0 时,我们称这样的边界为 Free boundary,对应的插值为 Natural Spline。
上述的两种边界条件都对应着统一的形式
2μ10⋮00λ02μ2⋮000λ12⋮00⋯⋯⋯⋱⋯⋯000⋮2μn000⋮λn−12M0M1M2⋮Mn−1Mn=g0g1g2⋮gn−1gn
其中,对于 Clamped boundary,有
λ0μng0gn=1=1=h16(f[x0,x1]−y0′)=hn6(yn′−f[xn−1,xn])
对于约束二阶导的情况,有
λ0g0gn=μn=0=2y0′′=2yn′′
或者可以直接解低两阶的方程组。
近似理论 Approximation Theory
给定 x1,…,xm 和 y1,…,ym,我们希望找到一个更简单的函数 P(x),使得 P(x)≈f(x)。
这个问题让人感觉很复杂,因为有两个问题:
我们应当把约等看成一种衡量条件,而简单则对应函数的某种形式,哪怕它直觉上并不是简单的。
一般情况下, m 是一个非常大的数,并且 yi 和 f(xi) 之间存在着误差。
一种可能的衡量约等的方法是,取残差 ri=yi−P(xi),所有的残差构成残差向量。我们通过它的某个范数来衡量约等的程度。
Discreate Least Squares Approximation
在本节的开始,为了讨论方便,我们先限定 P 的形式为一个多项式
P(x)=a0+a1x+…+anxn
并要求残差向量的二范数最小。为了计算方便,我们定义误差指标为
E2=i=1∑m(P(xi)−yi)2
可以看到, E2 是一个以 {ai} 为自变量的多元函数。如果我们希望 E2 取到最小值,我们至少需要它对于 ai 的导数都为 0。
为了方便起见,我们用矩阵的语言描述这个问题。
记
a=a0a1⋮an,x=11⋮1……⋮…x1nx2n⋮xmn
那么,我们就有
xa=p=P(x1)⋮P(xm)
如果我们再记
y=y1⋮ym
则有
E2=∥xa−y∥22=(aTxT−yT)(xa−y)=aTxTxa−2aTxTy+yTy
那么求导即有
E2′=2xTxa−2xTy
因此,这个条件可以整理为
(xTx)a=xTy
以上讨论中,我们要求用户指定的 n≤m−1,否则可能出现过拟合的现象。当恰好 n=m−1 时, Pn(x) 就是原函数的插值多项式, E2=0。
而实际上, P(x) 的形式可以不是一个多项式。
比如说,我们希望 P(x) 的形式为 P(x)=aeax。此时,我们可以这么处理(简记 P(x)=p ):
p⇒lnp=beax=lnb+ax
我们记
P=lnp,X=x,a1=a,a0=lnb
那么上面就被化成了
P=a0+a1X
的形式,就可以用之前的做法来解决了。
然而,这么做实际上有一个问题:沿用之前的做法的话,意味着我们认为 residual 为
i=1∑m(xi+a+lnb−lnyi)2
可在变换前,这个 residual 应当为
i=1∑m(beaxi−yi)
这两者并不等价。当前者取最小时,并不意味着后者取到最小。
Orthogonal Polynomials and Least Squares Approximation
过去,我们强调多项式的形式为
P(x)=a0+a1x1+…anxn
而现在,我们强调多项式作为一个线性空间中的一个向量的属性,并借此来定义广义多项式。
首先,我们定义多项式中线性无关的概念:
对于一组函数 {ϕ0(x),ϕ1(x),…,ϕn(x)},如果在区间 [a,b] 上,有
∀x,a0ϕ0(x)+a1ϕ1(x)+…+anϕn(x)=0⇔a0=a1=…an=0
则说这组函数是线性无关的。
显然地,如果 ϕi(x) 是一个 i 阶多项式,那么 {ϕ0(x),ϕ1(x),…,ϕn(x)} 是线性无关的。
对于任意一组线性无关的函数,我们可以认为它们构成了某个线性空间的一组基。而这些线性无关函数的线性组合,也就被定义为广义多项式。
另外,关于之前的残差,我们也进行广义化。我们为残差的每一项添加权重 ωi,即
E=i=1∑mωi(P(xi)−yi)2
如果我们突破采样点的限制,使用连续的形式,则可以使用权函数来定义残差。
E=∫abω(x)(P(x)−f(x))2
回顾之前用线性代数语言描述的残差,我们会发现,在离散情况下考虑多项式近似时,若令
ω=ω1ω2⋱ωm
则有
E=∥ωxa−ωy∥22
既然已经出现了范数和线性空间的表述,我们为何不定义点积?
(f,g)=⎩⎨⎧i=1∑mωif(xi)g(xi)∫abω(x)f(x)g(x)dx
自然地,当 (f,g)=0 时,我们说 f,g 正交。
那么, E=(P−y,P−y),我们想找的也就是使得这个内积最小的 P。
现在,我们再考虑 ωi=1 时广义多项式的近似。令 P(x)=a0ϕ0(x)+a1ϕ1(x)+…+anϕn(x),且对 f 近似,则原先关于 {ai} 导数为 0 的条件转化为
bij=(ϕi,ϕj)a0⋮an=(ϕ0,f)⋮(ϕn,f)
这看起来是个线性方程组。所谓最好的解线性方程组的方法就是不要解这个线性方程组,注意力惊人的我们注意到,当 {ϕi} 是一个单位正交基时,我们可以直接得到
a0⋮an=(ϕ0,f)⋮(ϕn,f)
不过,有时为了获得单位的性质,我们获取基的过程可能会引入过多的计算。因此,我们可以退而求其次,取正交基,此时相当于解一个系数矩阵为对角阵的线性方程组。
于是,求解合适的广义多项式近似的过程,也就变成了寻找合适的正交基的过程。而对于这个过程,我们有施密特正交化做指导。
根据施密特正交化,我们可以导出这样一个结论:
对于满足形式
ϕ0(x)≡1,ϕ1(x)=x−B1
的基,有递推关系
ϕk(x)=(x−Bk)ϕk−1(x)−Ckϕk−2(x)
其中
Bk=(ϕk−1,ϕk−1)(xϕk−1,ϕk−1),Ck=(ϕk−2,ϕk−2)(xϕk−1,ϕk−2)
注意点积隐含了 ωi。这里,我们通过上述过程获得了一组互相正交的基 ϕi,而对应的系数 ai 也就是
ai=(ϕi,ϕi)(ϕi,y)
在编程上,算法为

可以注意到,我们并没有每次重新计算误差,而是每一次减去一个 ai(ϕi,y) 的项。这得益于这组基的正交性。
Chebyshev Polynomials and Economization of Power Series
切比雪夫多项式
在之前,我们希望残差向量的二范数最小。现在,我们希望它的无穷范数最小。
这一考虑是很合理的。假设我们需要仿真一个结构的物理强度,我们当然不只是希望它的残差向量的二范数最小,因为平均会掩盖局部的问题——我们希望确定仿真误差的一个上界,因此会选择最小化无穷范数。
考虑一个多项式 P 和待近似的函数 f,如果在某个点 x0,有 P(x0)−f(x0)=±∥P−f∥∞,则称 x0 是偏移点 deviation point。
有这样一个结论:如果 f∈C[a,b],且 f 不是 n 阶多项式,那么就存在一个唯一的多项式 Pn,使得 ∥Pn−f∥∞ 取到最小。根据几何直觉,此时,必然同时有正的和负的偏移点。
Chevyshev Theorem 告诉我们,Pn 满足 ∥Pn−f∥∞ 最小,等价于 Pn 相对于 f 有至少 n+2 个正负交替的偏移点。这 n+2 个偏移点的横坐标构成的序列被称为 Chebyshev alternating sequence。
此时, Pn 与 f 必然有 n+1 个交点。确定了这些交点,就能通过插值确定 Pn。既然我们并不需要保持增加点后多项式形式的连续性,拉格朗日插值就是一个好的选择。
那么,应该怎么取点呢?
审视一下我们面对的问题。我们可以轻松地写出拉格朗日插值的残差为
∣Pn(x)−f(x)∣=∣Rn(x)∣=(n+1)!f(n+1)(ξ)i=0∏n(x−xi)
我们希望取合适的点 x0,…,xn,使得这个残差的值尽可能的小。虽然 ξ 是和 x 相关的量,但是我们没法描述其中的关系,因此,我们退而求其次,尝试最小化
i=0∏n(x−xi)
在这里,可以发现,我们实际上做的近似并没有真的使得 ∥Pn−f∥∞ 取到最小。我们只是尝试着最小化了它的上界。
根据切比雪夫定理,我们需要 ∏i=0n(x−xi) 拥有上下振荡,且绝对值相同的 n+2 个极值点。在几何直觉上,这让我们联想到三角函数。
不妨取一个余弦函数 cos(nθ),我们会发现,它在 θ∈[0,π] 中有 n+1 个极值点
n0π,nπ,n2π,…,nnπ
此时,我们做一次换元,令 x=cosθ,那么就会有 x∈[−1,1],且原函数转化为
Tn(x)=cos(narccosx)
这就是所谓的切比雪夫多项式。利用三角函数的递推关系,我们可以得到一个较为方便的递推式
T0(x)T1(x)Tn+1(x)=1=x=2xTn(x)−Tn−1(x)
然而,你可能发现了, n+1 和 n+2 数量对不上。不过,这倒也好说,我们只要改用 Tn+1 就可以了。再通过一些换元,我们就可以把 x 的范围限制在 [−1,1],从而利用切比雪夫多项式来获得一个残差向量的无穷范数上界最小化的近似。注意观察切比雪夫多项式 Tn+1 的最高次项系数为 2n,所以对
i=0∏n(x−xi)
最小化的结果是取 Tn+1 的 n+1 个根,此时为
2nTn+1(x)
以此为例:尝试找到 [0,1] 上关于 f(x)=ex 的最佳近似多项式,使得绝对误差不超过 5×10−5。
首先,我们希望把自变量的范围变成 [−1,1],因此做一个换元 x=2t+1,此时有考虑残差的上界表达式为
g(t)=f(x)=e2t+1
(n+1)!2ng(n+1)(t)max=(n+1)!22n+1e2t+1max=(n+1)!22n+1e
当 n=4 时,已经符合条件。此时,有 T5(t) 的根为
cos(10π),cos(103π),cos(105π),cos(107π),cos(109π)
将它们转化成对应的 x,然后用这些 x 作为插值点来计算 L4(x) 即可。
可以发现,我们成功找到了一种方法,来保证了误差在某个确定的范围内,且每升一阶,确定减小范围为原来的 21,这是一件很棒的事情。
在过去,我们讨论的插值总是默认了用户会提供一些采样点。然而,在切比雪夫多项式的使用中,我们发现,使用的采样点是自己决定的。事实上,大多数优秀的插值方法,它的采样点都不依赖用户输入,而是自己选取。合适的采样点选取对于提高精度、减少计算非常重要。
来点题外话。不知道你有没有注意到一件有趣的事情:拉格朗日插值的余项
(n+1)!f(n+1)(ξ)i=0∏n(x−xi)
和泰勒展开的余项
(n+1)!f(n+1)(ξ)(x−x0)n+1
在形式上惊人的接近。事实上,当区间足够小时,两者是等价的。在几何直觉上,我们不妨把拉格朗日插值看成泰勒展开延拓到区间上的结果。
幂级数的经济化
幂级数的经济化(Economization of Power Series)指的是对于近似 Pn(x)≈f(x),降低 P 的阶数,且保证精度下降的最小。
对于一个近似 Pn,我们可以通过让它减去一个多项式 Qn 的方式,使得它变成低一阶的多项式 Pn−1。显然,一个非常好的思路就是让它减去一个切比雪夫多项式。
以此为例:对于 f(x)=ex,x∈[−1,1] 的近似
P4=1+x+2x2+6x3+24x4
尝试通过经济化的方式把它的次数降到 2。
首先,有
T4=8x4−8x2+1
于是我们消去 241×81T4(x),得到
P3=192191+x+2413x2+61x3
再取
T3=4x3−3x
消去 61×41T3,就得到了
P2=2413x2+89x+192191
数值微积分
数值微分 Numerical Differentiation
一个很自然的想法是直接用
f′(x0)=h→0limhf(x0+h)−f(x0)
当 h 为正,就说这是一个 forward 的微分,相反,则为 backward 的微分。
另一种想法是,首先使用插值多项式来逼近这个函数,然后用这个插值多项式的导数作为函数的导数。
如果我们选择用 x0,x0+h 两个点来做拉格朗日插值,可以得到
f(x)=hf(x0)(x0+h−x)+f(x0+h)(x−x0)+2(x−x0)(x−x0−h)f′′(ξ)
对它求导,可以得到
f′(x)=hf(x0+h)−f(x0)−2hf′′(ξ)
这样,我们就得到了一个关于误差的估计,它是 O(h) 的。
如果我们尝试再多添加一个采样点,那么情况会好很多:
f(x0+h)f(x0−h)=f(x0)+f′(x0)h+21f′′(x0)h2+61f′′′(x0)h3+241f(4)(ξ1)h4=f(x0)−f′(x0)h+21f′′(x0)h2−61f′′′(x0)h3+241f(4)(ξ2)h4
两式相减(这时余项取三阶),可以得到
f′(x0)=2hf(x0+h)−f(x0−h)−121(f′′′(ξ1)+f′′′(ξ2))h2=2hf(x0+h)−f(x0−h)−61f′′′(ξ)h2
两式相加,同理可以得到
f′′(x0)=h2f(x0−h)+f(x0+h)−2f(x0)−121f(4)(ξ)h2
可以看到,我们只是添加了一个取样点,就成功地把误差从 O(h) 降低到了 O(h2)。
数值微分是不稳定的。尽管我们希望通过增加取样点的方式来提升近似精度,但是这样做的同时,会导致舍入误差也增大。
数值积分 Numerical Integration
一个简单的思路是选一些点,然后做一个拉格朗日插值,再做一个积分。
在数值积分中,我们有一个精确度 precision 的概念。当一个离散的积分表达式(quadrature formula)给定,且它对于 xk,k=0,1,…,n 是完全精确的,我们就说它的精确度为 n,或者说它是 n 阶精确的。
显然,对于一个 n 阶的拉格朗日插值导出的积分表达式,它的精确度为 n。
∫abf(x)dx=∫abk=0∑nf(xk)Lk(x)dx+∫abi=0∏n(n+1)!f(n+1)(ξ(x))dx
这一个表达式同时展示了数值积分的计算值和误差范围。在计算部分,我们把积分的操作提前,这样,我们就可以提前计算每一个 f(xk) 对应的系数
ak=∫abLk(x)dx
于是有
∫abf(x)dx≈k=0∑nakf(xk)
在讨论泛化的积分表达式前,让我们先分别关注一下通过一阶和二阶拉格朗日多项式得到的特例。
Trapezoidal Rule
我们记 x0=a,x1=b,h=b−a。此时,根据一阶拉格朗日多项式,我们可以得到
∫abf(x)dx=2h(f(x0)+f(x1))−12h3f′′(ξ)
其中,误差项的转变应用了积分中值定理。
∫x0x1f′′(ξ(x))(x−x0)(x−x1)dx=f′′(ξ)∫x0x1(x−x0)(x−x1)dx for some ξ∈(x0,x1)
由于误差项是二阶导,它的精确度为 1。
Simpson’s Rule
考虑 x0=a,x1=a+h,x2=b,h=2b−a,根据二阶拉格朗日多项式,可推导得到
∫x0x2f(x)dx=3h(f(x0)+4f(x1)+f(x2))−90h5f(4)(ξ)
你可能会惊讶于它的精确度居然为 3。这是由于均匀取点而产生的特殊现象。在误差累积的过程中,奇数次项的积分被消去,因此,最终的误差阶数总是奇数阶的。
一般形式
当 n 为偶数时,有
∫abf(x)dx=i=0∑naif(xi)+(n+2)!hn+3f(n+2)(ξ)∫0nt2(t−1)…(t−n)dt
当 n 为奇数时,有
∫abf(x)dx=i=0∑naif(xi)+(n+1)!hn+2f(n+1)(ξ)∫0nt(t−1)…(t−n)dt
上述均匀取点还有一个好处,就是它让我们不再需要考虑点的选取,表达式只与取点数量和区间长度有关,这使我们的运算更为方便了。
分段(Composite)数值积分
多项式次数高了容易振荡,所以我们可以尝试分段取积分。简单的方法是把区间分成 n 段,然后在每一段上都应用辛普森法则,然后取加和。
令 f∈C4[a,b], n 为偶数, h=nb−a, xj=a+jh,则有
∫abf(x)dx=3hf(a)+2j=1∑2n−1f(x2j)+4j=1∑2nf(x2j−1)+f(b)−180nh5f(4)(ξ)
系数 4 来自于辛普森法则的中间项,系数 2 来自两边同时运用辛普森法则,系数 1 则是因为边界。
使用梯形法则的情况如下:
∫abf(x)dx=2h(f(a)+2j=1∑n−1f(xj)+f(b))−12nh3f′′(ξ)
Composite Integration 是稳定的。这意味着,我们可以放心地增加分段的段数,而不需要担心误差变得过大。对于 [a,b] 上的积分,分段积分的误差有上限
(b−a)ϵ
其中 ϵ 是每次计算的误差上限。
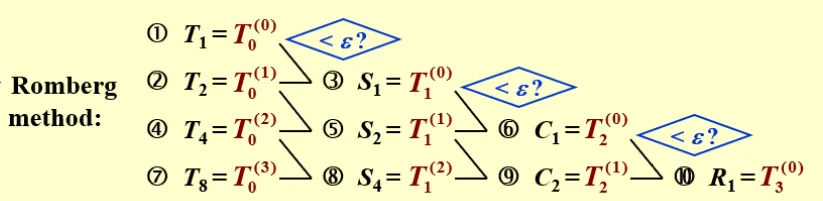
龙伯格积分 Romberg Integration
还记得埃德金加速吗?当我们发现一个收敛序列之后,我们可以对其中的某些关键条件做一些扰动,从而得到一些新的和真值、误差有关的关系式。通过合理的方法消去误差,我们可以得到一个新的真值的近似表达式。这个新的表达式就可以用于收敛的加速。
我们重记分段积分时的梯形法则为
A=Tn−12n2(b−a)3f′′(ξn)
当我们对区间数量 n 做一个扰动,使它变成 2n,就会得到
A=T2n−48n2(b−a)3f′′(ξ2n)
如果我们近似取 f′′(ξn)≈f′′(ξ2n),就可以得到
A=34T2n−Tn
于是,我们就可以通过这个式子作为一个 A 的近似解。
更进一步地,我们发现,上面得到的式子中, T2n 与 Tn 前的系数只与误差项的次数有关。如果我们记
Sn=34T2n−Tn
就有 Sn 的误差项次数为 4。因此,我们可以进一步加速收敛:
⎩⎨⎧SnCnRn=4−14T2n−Tn=42−142S2n−Sn=43−143C2n−Cn
而具体的递推思路如下图:
理查德外推是对如龙伯格积分情形的一种推广。假设我们有一个 T0(h) 来近似真解 I,且对于某个变量 h,它的 truncation error 满足
T0(h)−I=α1h+α2h2+α3h3+…
那么,我们就可以选择对 h 做一个扰动,得到
T0(2h)−I=α12h+α2(2h)2+α3(2h)3+…
于是乎,我们可以得出这样一个式子:
T1(h)=2−12T0(2h)−T0(h)=I+β1h2+β2h3+…
每一次外推,收敛阶数就上升一阶。这样的外推过程可以不断地进行下去,于是我们得到外推序列的递推式
Tn(h)=2n−12nTn−1(2h)−Tn−1(h)=I+t1hn+1+t2hn+2+…
Adaptive Quadrature Method
在分段积分的时候,我们注意到,对于不同部分的函数,取积分的误差是不一样的。因此,我们倾向于对积分误差可能大的部分取更细的划分。问题是,怎样算“大”?
我们可以简单地利用误差的密度来选出“大”的部分。如果积分
∫abf(x)dx
的误差为 ϵ,那么对于其中的一段长度为 h 的区间,它可以分配到误差 hb−aϵ。如果这一块实际的误差大于它,就说明它属于“大”的部分。这里的 b−aϵ 就称之为误差密度。
此时,另一个问题就来了:这一块实际的误差又怎么评估?
举辛普森法则为例吧,我们知道它的误差表达式为
90h5f(4)(ξ)
它来自于
∫abf(x)dx=S(a,b)−90h5f(4)(ξ)
如果我们再将这个区间二分,我们可以得到
∫abf(x)dx=S(a,2a+b)+S(2a+b,b)−16190h5f(4)(ξ′)
如果我们认为 ξ≈ξ′,就可以得到
ϵ=151S(a,b)−S(a,2a+b)−S(2a+b,b)
在直觉上,如果我们先算一遍一个区间,再尝试缩小一些算,如果相差不大,就说明误差不会很大,反之,误差就可能比较大了。嗯,很符合直觉。
这体现了一种后验的自适应:我们尝试再做一遍,获取额外的信息,从而进行评估。在完成这样的评估之后,我们不要浪费计算的
S(a,2a+b)+S(2a+b,b)
使用
∫abf(x)dx−(S(a,2a+b)+S(2a+b,b))<ϵ
那有没有什么先验的方法呢?一种思路是训练一个 AI,然后把表达式扔给 AI,让它估计一下什么区间分细一些比较合适。
Gaussian Quadrature
类似于切比雪夫,高斯积分法是自己确定采样点的。
我们的目标是:找到一个表达式
∫abω(x)f(x)dx≈k=0∑nAkf(xk)
使得它取 n+1 个采样点时,精度有 2n+1,即对于 f∈P2n+1,积分式的误差为 0 。
首先,我们考虑这个问题的可解性。如果要求精度是 2n+1,那么就要解决多项式系数中 2n+2 个自由度。同时,我们的
k=0∑nAkf(xk)
中,除了 Ak 能够提供自由度外,由 xk 决定的 f(xk) 也可以提供自由度,恰好也为 2n+2。
我们考虑
f(x)=a0x0+a1x1+…+a2n+1x2n+1
此时,如果方程组
∫abω(x)⋅x0dx∫abω(x)⋅x1dx∫abω(x)⋅x2n+1dx=k=0∑nAk⋅xk0=k=0∑nAk⋅xk1…=k=0∑nAk⋅xk2n+1
有解,那么我们就找到了一组合适的 {Ak} 与 {xk}。
然而,这个方程组是非线性的,看起来不是很好解。因此,我们引入如下的定义:
- 对于某个点组 {xk},如果存在某组 {Ak},使得上述 2n+1 阶精度条件成立,那么点组 {xk} 被称为高斯点。
我们接下来证明, {xk} 为高斯点,等价于对于任意的低于 n 阶的多项式 Pm,有
∫abω(x)Pm(x)W(x)dx=0
其中
W(x)=k=0∏n(x−xk)
换而言之,以 ω(x) 作为权函数时, Pm(x) 与 W(x) 正交。
首先,我们证明必要性。对于任意的 Pm,我们发现, Pm(x)W(x) 这个整体恰好是一个次数不超过 2n+1 的多项式。因此,根据高斯点的定义,我们有
∫abω(x)Pm(x)W(x)dx=k=0∑nAkPm(xk)W(xk)=0
即得 Pm(x) 与 W(x) 正交。
接着证明充分性:对于任意的 Q∈P2n+1,我们可以利用多项式除法将它分解成
Q=W(x)q(x)+r(x)
在等式两边乘上 ω(x) 并积分,我们得到
∫abω(x)Q(x)dx=∫abω(x)W(x)q(x)dx+∫abω(x)r(x)dx=∫abω(x)r(x)dx
在这里,我们注意到, r(x) 的阶数不超过 n。因此,我们可以直接利用插值构造出一组合适的 {Ak},使得
∫abω(x)r(x)dx=k=0∑nAkr(xk)
注意到 Q(xk)=r(xk) 此时,我们已经得到了
∫abω(x)Q(x)dx=k=0∑nAkQ(xk)
这已经与高斯点定义的形式吻合。同时,我们知道,拉格朗日插值系数只与取样点有关,因此 {Ak} 是确定的。于是,充分性得证。
现在,我们发现,我们已经将问题的核心转移到如何寻找高斯点了。
尝试用 n=1 的高斯积分近似 ∫01xf(x)dx
我们随便选取线性无关的基 1,x,并要求它们都与
ϕ(x)=x2+ax+b
正交。
于是,我们解方程组
∫01x(x2+ax+b)dx∫01x(x3+ax2+bx)dx=0=0
解得 a=−910,b=215。
此时,我们需要的 W(x)=x2−910x+215=(x−x0)(x−x1),于是可以解得 x0=0.8212,x1=0.2899。
然后,我们通过取 f(x)=1,x 回代的方式,就可以解出 A0=0.3891,A1=0.2776。
在 PPT 中,并没有随便选取线性无关的基,而是要求了这是一组正交基,这应该是站在计算机计算的角度考虑问题了。
很自然的,我们会萌生出首先解好一些常见的权函数对应的高斯积分形式。
勒让德多项式 Legendre Polynamials 是积分区间为 [−1,1],且权函数取 ω(x)≡1 时的高斯积分的 W(x)。
勒让德多项式的形式如下:
Pk(x)=2kk!1dxkdk(x2−1)k
且有
(Pk,Pk)=2k+12
我们可以使用递推式
P0=1,P1=x,(k+1)Pk+1=(2k+1)xPk−kPk−1
来快速地导出某个阶数的勒让德多项式。采用 Pn+1 的根作为高斯点的高斯积分公式被称为 Gauss-Legendre quadrature formula。
类似于之前对切比雪夫多项式的处理,当积分区间不为 [−1,1] 时,可以通过定义域映射的方式处理,从而用勒让德多项式解决问题。
事实上,切比雪夫多项式就是取 ω(x)=1−x21 时高斯积分的 W(x)。
微分方程 Differential Equations
带初值条件的一阶常微分方程如下:
⎩⎨⎧dtdyy(a)=f(t,y)t∈[a,b]=α
一种理解是把第一个等式看成一个二维空间中的向量场。决定一个初始位置,就会有对应的运动轨迹。
我们的目标是,计算 y(t) 在一系列网点(mesh points) 的近似。即:计算
ωi≈y(ti)=yi,i=1,…,n
Libschitz Condition
为了引入对何种一阶常微分方程存在唯一解的说明,我们引入 Libschitz condition 的定义:
如果在 R2 的子集 D 内,存在一个常数 L>0 使得对于任意点 (t,y1),(t,y2),都有
∣f(t,y1)−f(t,y2)∣≤L∣y1−y2∣
那么我们就说 f(t,y) 对于变量 y 在 D 上满足 Lipschitz condition,并称 L 是 f 的 Lipschitz constant。
直观地说,在定义域 D 内,函数 f(t,y) 关于 y 的偏导被限制在了一个范围内。(当然,这要求 f 在 D 上是连续的。)
如果 f(t,y) 在 D 上连续,且 f 满足 Lipschitz Condition,那么 IVP 问题
y′(t)=f(t,y),a≤t≤b,y(a)=α
就拥有一个唯一解 y(t)。
良定义 well-posed
在 Libschitz Condition 的基础上,我们引入良定义的定义:
IVP
y′(t)=f(t,y),a≤t≤b,y(a)=α
是良定义的,若
- 这个问题存在唯一解
- 对于任意的 ϵ>0,都存在正常数 k(ϵ) 使得对于任意满足
∣ϵ0∣<ϵ,∣δ(t)∣<ϵ with t∈[a,b]
的 ϵ0,δ(t),都存在一个唯一的解 z(t),使得
z′(t)=f(t,z)+δ(t),z(a)=α+ϵ0,∣z(t)−y(t)∣<k(ϵ)ϵ
那么这个问题被称作是良定义(well—posed problem)的。
乍一看,良定义的第二条性质似乎比较复杂。我们可以这样在几何上理解:
- ϵ0 是对初值条件的微小扰动
- δ(t) 是对 f(t,y) 构成的向量场做了一个微小扰动。
只要这两个微小扰动的范围被 ϵ 控制住,那么解的轨迹的偏离 ∣z(t)−y(t)∣ 就能够被控制在 k(ϵ)ϵ 内。
因此,第二条性质实际表明了,在初始条件或方程发生微小的变化时,解的变化是可控的。
可以证明,对于 D 上连续的 f(t,y) 和相应的 IVP
y′(t)=f(t,y),a≤t≤b,y(a)=α
只要 f 满足 Lipschitz Condition,那这个问题就是良定义的。
欧拉法
根据微分的定义,我们可以使用如下的近似:
y′(t0)≈hy(t0+h)−y(t0)
如果我们取 h=t1−t0,那么就会有
y(t1)≈y(t0)+hy′(t0)=α+hf(t0,α)
那么实际上,我们已经获得了一个递推关系:
ω0=α,ωi+1=ωi+hf(ti,ωi)
这里,我们用 ωi 表示了 y(ti) 的近似。Lipschitz Condition 保证了 ωi 和 y(ti) 的误差不会过大。
如果 f 是连续的,且它满足 Lipschitz 条件,则有
∣yi−ωi∣≤2LhM(eL(ti−t0)−1)
其中 M 是 ∣y′′(t)∣ 的上界。二阶导的计算可以通过
y′′(t)=dtdy′(t)=dtdf(t,y(t))=∂t∂f(t,y(t))+∂y∂f(t,y(t))⋅f(t,y(t))
通过上面的误差估计公式,我们可以看到,当 h 取的较小时,误差可能较小。然而,当我们注意到舍入误差时,就会发现, h 取的过小同样会引入问题。
当我们引入舍入误差,有表达式
ω0ωi+1=α+δ0=ωi+hf(ti,ωi)+δi+1
此时,记舍入误差的绝对值上界为 δ,则上面的误差被更新为
∣yi−ωi∣≤L1(2hM+hδ)[eL(ti−a)−1]+∣δ0∣eL(ti−a)
高阶泰勒方法
我们假设存在这样的递推式:
ω0=α,ωi+1=ωi+hϕ(t,ωi)
并且,在估计误差时,我们总是假设当前的点是精确的,只考虑求下一个点时带来的误差:
τi+1(h)=hyi+1−yi−hϕ(t,yi)=hyi+1−yi−ϕ(ti,yi)
这样的误差忽略了全局求解带来的对当前点的误差影响,被称为 Local Truncation Error。
我们之前提到的欧拉法中的递推式就是取 ϕ=f 的情况。如果我们尝试为欧拉法计算 Local Truncation Error,可以简单地使用泰勒展开:
yi+1=yi+hf(ti,yi)+2h2f′(ti,yi)+…+n!hnf(n−1)(ti,yi)+(n+1)!hn+1f(n)(ξi,y(ξi))
于是,欧拉法的 Local Truncation Error 为 O(h)。
那么,我们很自然地想到,可以调整递推式的形式,使得它与泰勒展开的形式接近,这样就可以利用余项的阶数评估 Local Truncation Error 的阶数。于是,我们就得到了所谓的高阶泰勒方法:
ω0ωi+1T(n)(ti,ωi)=α=ωi+hT(n)(ti,ωi)=f(ti,ωi)+2hf′(ti,ωi)+…+n!hn−1f(n−1)(ti,ωi)
可以看到,对于 n 阶的高阶泰勒方法,它的 Local Truncation Error 为 O(hn)。
隐式欧拉法
在欧拉法的迭代中,我们改用下一个点的导数来替换当前点的导数,于是就得到
ωi+1=ωi+hf(ti+1,ωi+1)
这里我们无法直接得到 ωi+1 的值,而是需要解上述的关于 ωi+1 的方程。这也是这种方法被称为隐式欧拉法的原因。
我们可以得到,这样的隐式欧拉法对应的 LTE 为 −2hy′′(ξi)。
那么,既然隐式欧拉法的求解比显式欧拉法的求解更为复杂,而 LTE 的阶数并没有增加,我们为什么还需要它呢?
实际上,类似于之前均匀取点抵消误差的思路,我们注意到欧拉法的 LTE 为 2hy′′(ηi),如果我们将它们结合起来,岂不是可以消去这些 O(n) 的项,从而获得 O(n2) 的 LTE?
梯形法
梯形法将一阶的显式欧拉法和隐式欧拉法做了结合,其递推式为:
ωi+1=ωi+2h[f(ti,ωi)+f(ti+1,ωi+1)]
其 LTE 阶数上升为 2。
然而,如果我们这么做,那么每一步还是要引入一个复杂的方程求解过程。有没有什么办法减少解方程的次数,从而减小求解开销呢?
Double-step 方法
在之前有关微分的部分,我们提到,如果多取一个采样点,就可以得到相比取 2 个采样点高一阶的精度。因此,我们可以把这个性质利用起来:
⇒y′(t0)=2h1[y(t0+h)−y(t0−h)]−6h2y(3)(ξ1)y(t2)≈y(t0)+2hf(t1,y(t1))
这样,我们也就得到了递推式
ωi+2=ωi+2hf(ti+1,ωi+1)
当我们取 ωi=yi,ωi+1=yi+1 时,可以求得 LTE 为 O(h2)。
因此,我们可以先用一些方法求取精度相对较高的初值 ω1,然后再使用较为简单的 double-step 方法。
Runge-Kutta 方法
在之前的 single-step 的递推式中,我们总是用单个的斜率和权重 1 来计算下一个点的位置。我们可以拓展这个思路,选择使用多个斜率、多个权重计算下一个点。为了简化问题的讨论,我们不妨就取两个点的斜率。
⎩⎨⎧ωi+1K1K2=ωi+h(λ1K1+λ2K2)=f(ti,ωi)=f(ti+ph,ωi+phK1)
我们总是希望这个方法的 LTE 阶数尽可能的高。因此,我们针对 LTE 做分析:
将 K2 泰勒展开:
K2=f(ti+ph,yi+phK1)=f(ti,yi)+phft(ti,yi)+phK1fy(ti,yi)+O(h2)=y′(ti)+phy′′(ti)+O(h2)
于是,我们就有
ωi+1=yi+(λ1+λ2)hy′(ti)+λ2ph2y′′(ti)+O(h3)
自然地,我们会要求它和 yi+1 的泰勒展开接近:
yi+1=yi+hy′(ti)+2h2y′′(ti)+O(h3)
那么就有方程
⎩⎨⎧λ1+λ2λ2p=1=21
如上方程拥有无穷多组解,而通过如上方法获得的解法被称为二阶的 Runge-Kutta 方法。
- 一个经典的选择是 p=1,λ1=λ2=21。这个选择被称作 Modified Euler’s method 或 Heun’s Method。
ωi+1=ωi+2h[f(ti,ωi)+f(ti+h,ωi+hf(ti,ωi))]
- 另一个选择是 p=21,λ1=0,λ2=1,这个选择被称作 Midpoint Method。
ωi+1=ωi+hf(ti+2h,ωi+2hf(ti,ωi))
而当我们继续拓展 K 的数量,我们就会得到如下的方程组:
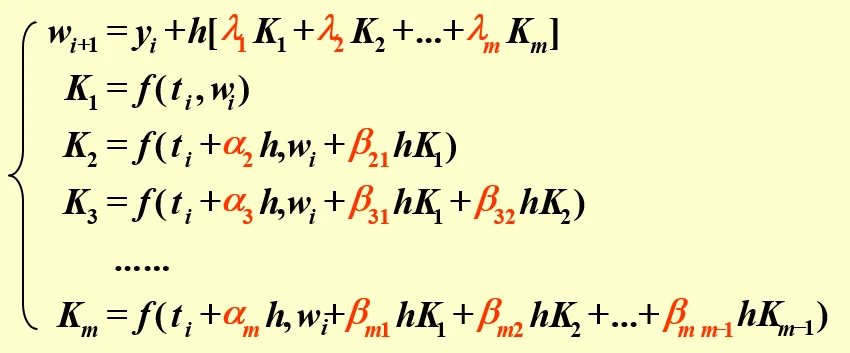
经过权衡,最流行的 Runge-Kutta 方法为 Classical Runge-Kutta Order 4 Method,也就是
⎩⎨⎧ωi+1K1K2K3K4=ωi+6h(K1+2K2+2K3+K4)=f(ti,ωi)=f(t+2h,ωi+2hK1)=f(ti+2h,ωi+2hK2)=f(ti+h,ωi+hK3)
Runge-Kutta 法的 LTE 阶数并不是线性增长的,它满足如下规律:

由于这个方法对误差的估计基于泰勒展开,我们需要 y 足够光滑。阶数越高,对光滑程度的要求也就越高。因此,类似于分段积分的思路,我们更倾向于在小步长内使用较低阶数的 Runge-Kutta,而非在大步长内使用较高阶数的 Runge-Kutta。
多步方法
我们考虑使用之前更多个已得到结果的项来计算下一项。用数学表达式来表示,也就是把递推式变成
ωi+1=a0ωi+a1ωi−1+…+am−1ωi+1−m+h(b0fi+1+b1fi+…+bmfi+1−m)
其中 fi=f(ti,ωi)。当 b0=0 时,这是一个显式方法,否则为一个隐式方法。
在计算 LTE (τ(h)) 时,我们假设之前的计算结果都是准确的,于是有
τi+1(h)=hyi+1−(a0yi+…+am−1yi+1−m)−(b0fi+1+b1fi+…+bmfi+1−m)
积分思路
在讨论显式方法时,如果我们选择利用 (ti,fi),(ti−1,fi−1),…,(ti+1−m,fi+1−m) 这 m 个点做一个牛顿插值,就可以得到插值多项式 Pm−1 和余项 Rm−1。那么,下一个点的 y 就可以通过积分的方法来近似表示:
∫titi+1f(t,y(t))dt=h∫01Pm−1(ti+sh)ds+h∫01Rm−1(ti+sh)ds⇒ωi+1τi+1(h)=ωi+h∫01Pm−1(ti+sh)ds=∫01Rm−1(ti+sh)ds
其中 s∈[0,1]。
举个例子,如果我们尝试得到一个显式的两步方法,那么我们可以先对 (ti,fi),(ti−1,fi−1) 取牛顿插值,即
P1(ti+sh)=fi+s(fi−fi−1),ti−ti−1=h
那么,通过积分,我们可以得到 ωi+1 的近似表达式
ωi+1=ωi+h∫01P1(ti+sh)ds=ωi+h(23fi−21fi−1)
而 LTE 则可以表示为(下面的转化中使用了中值定理)
τi+1=∫01R1(ti+sh)ds=∫01dt2d2f(ξi,y(ξi))2s(s+1)h2ds=125h2y′′′(ξi′)
这个方法被称为 Adams-Bashforth two-step explicit method。
可以注意到,其实通过交换积分顺序的方式, ωi+1−ωi 可以被表示成 fi+1,fi,fi−1,…,fi+1−m 的线性组合,且它们的系数可以被提前计算出来。下面的表展示了使用显式方法(取 fi+1 的系数为 0)时的一些系数:

其中 τi+1=Amhmy(m+1)(ξi)。
一个常用的方法为 Adams-Bashforth Four-Step Explicit Method,即
ωi+1=ωi+24h(55fi−59fi−1+37fi−2−9fi−3)
当我们使用隐式方法时,则需要改为对 (ti+1,fi+1),(ti,fi),…,(ti+1−m,fi+1−m) 这 m+1 个点做插值。类似地,我们可以得出这样一张系数表:
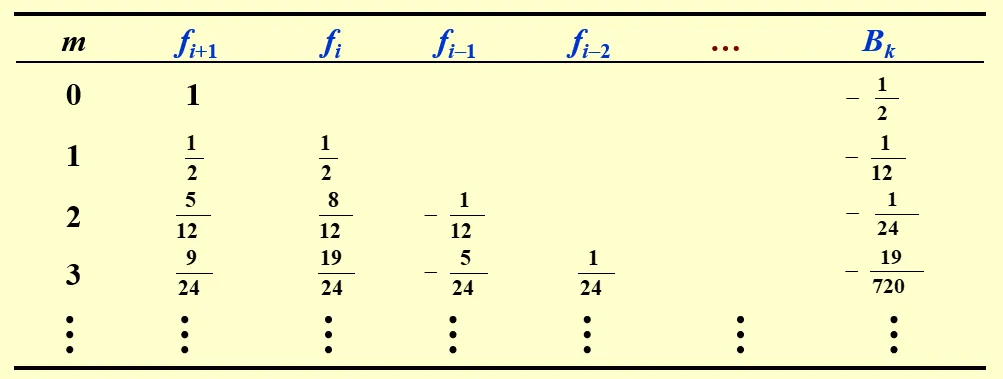
其中 τi+1=Bmhm+1ym+2(ξi)。
Adams-Moulton Three-Step Implicit Method 为
ωi+1=ωi+24h(9fi+1+19fi−5fi−1+fi−2)
类似于之前将显式方法和隐式方法结合的思路,我们也可以通过线性组合显示方法和隐式方法的解,使得 LTE 的阶数往上升一阶。一个使用多步方法的流程是,首先用 Runge-Kutta 法计算前 m 个点,然后,首先使用显式方法预测第 m+1 个点,再用隐式方法去 refine 这个结果。之后,每一个新的点的计算都在前面的基础上往下做。
泰勒展开思路
再放一遍表达式:
ωi+1=a0ωi+a1ωi−1+…+am−1ωi+1−m+h(b0fi+1+b1fi+…+bmfi+1−m)
我们可以依旧采用泰勒展开的思路,对 yi−1,…,yi+1−m 与 fi+1,fi−1,…,fi+1−m 全部关于 ti 进行泰勒展开,然后利用待定系数法求解一组合适的 {ak},{bk}。
以求解拥有形式
ωi+1=a0ωi+a1ωi−1+a2ωi−2+h(b0fi+b1fi−1+b2fi−2+b3fi−3)
的递推式为例:
我们进行一系列泰勒展开,有:
yiyi−1yi−2fifi−1fi−2fi−3yi+1========yiyiyiyi−hyi′−2hyi′yi′yi′yi′yi′+hyi′+21h2yi′′+2h2yi′′−hyi′′−2hyi′′−3hyi′′+21h2yi′′−61h3yi′′′−34h3yi′′′+21h2yi′′′+2h2yi′′′+29h2yi′′′+61h3yi′′′+241yi′′′′+32h4yi′′′′−61h3yi′′′′−34h3yi′′′′−29h3yi′′′′+241yi′′′′+O(h5)+O(h5)+O(h4)+O(h4)+O(h4)+O(h5)
我们通过 yi,yi′,yi′′,yi′′′,yi′′′′ 前的系数,可以构造出 5 个等式,而未知数 a0,a1,a2,b0,b1,b2,b3 则有 7 个。因此,这个方程的解并不唯一。
- a1=a2=0 时,为 Adams-Bashforth explicit method
- a1=a2=0,且将 fi−1 展开式替换成 fi+1 展开式时,为 Adams-Moulton implicit method
- 把 fi−3 展开式替换成 yi−3 展开式时,我们可以得到另一族解,其中包括 explicit Milne’s method
ωi+1=ωi−3+34h(2fi−fi−1+2fi−2)
其 LTE 为 4514h4y(5)(ξi),ξi∈(ti−3,ti+1)
- a1=1,a2=0 时,得到 Simpson implicit method
ωi+1=ωi−1+3h(fi+1+4fi+fi−1)
其 LTE 为 −90h4y(5)(ξi),ξ∈(ti−1,ti+1)
这样的解怎么都列不完,重要的是掌握方法。
微分方程的高阶方程/系统
一阶微分方程的 m 阶系统
以下是一个一阶微分方程的 m 阶系统:
⎩⎨⎧u1′(t)…um′(t)u1(a)…um(a)=f1(t,u1(t),…,um(t))=…=fm(t,u1(t),…,um(t))=α1=…=αm
如果我们使用向量的形式写这些等式,就可以把它们转化成我们熟悉的形式:
记
y=u1⋮um,f=f1⋮fm,α=α1⋮αm
则有
{y′(t)y(a)=f(t,y)=α
形式上的熟悉带来求解上的熟悉。
高阶微分方程
以下是一个 m 阶的微分方程:
{y(m)(t)=f(t,y,y′,…,ym−1)y(a)=α1,y′(a)=α2,…,y(m−1)(a)=αm
m 阶就需要 m 个初值。
我们可以通过变量替换的方式,将求解 m 阶微分方程的问题转化为求解一阶微分方程的 m 阶系统:
取 uk(t)=y(k−1)(t),则有
{y′(t)y(a)=f(t,y)=α
其中
y=u1⋮um−1um,f=u2⋮umf(t,u1(t),…,um(t)),α=α1⋮αm−1αm
例题:使用 modified Euler’s method 求解下面的问题,其中 h=0.1:
y′′y(0)=2y′−y+tet−1.5t+1,0≤t≤0.2=0,y′(0)=−0.5
为了方便,这里只给出 t=0.1 的解:
我们列出
y=(u1u2),f=(u22u2−u1+tet−1.5t+1)
于是,就有
K1K2=f(0,(0−0.5))=(−0.50)=f(0.1,(0−0.5)+0.1(−0.50))=(−0.50.1e0.1−0.1)
那么
y(0.1)=(−0.50)+0.1×21[(−0.50)+(−0.50.1e0.1−0.1)]=(−0.550.005−0.005e0.1)
整体思路是类似的,只不过是计算向量化了。
稳定性
精确的算法未必是好的算法。局部高精度方法不一定全局精度高。
一致与收敛
考虑一个单步的微分方程解法,我们称它是一致(Consistent)的,如果它的 LTE τi(h) 满足
h→0lim1≤i≤nmax∣τi(h)∣=0
也就是说,对于一个一致的微分方程解法,我们可以通过减小采样间隙的方式来无限降低它的局部截断误差。
更进一步地,如果我们直接要求
h→0lim1≤i≤nmax∣yi−ωi∣=0
那我们称这个解法是收敛(Convergent)的。
也就是说,对于一个收敛的微分方程解法,我们可以通过减小采样间隙的方式来无限降低它的解与真值之间的误差。
对于多步解法,以上定义相同。
稳定
如果一个 ODE 方法的初值条件受到一个小的扰动,它的全部的近似结果受到的扰动也较小,那么它对应的求解方法是稳定(stable)的。
上面的定义显然是模糊的,我们首先需要讨论一个合理的评判规则。一个 ODE 方法的稳定性是相对于测试方程(test equation) 而言的。一个常见的测试方程是线性标量方程,即:
y′=λy,y(0)=α,Re(λ)<0
我们假设舍入误差仅仅在初值点被引入。如果对于某个取值范围的 H=hλ,由初值误差带来的最终计算结果的误差随着采样数的增加而减小,那么我们就说这个 ODE 方法关于 H 是绝对稳定(absolutely stable) 的。满足如上条件的 H 的范围越大,ODE 方法也就越稳定。
在几何直觉上:
- 显式方法中,下一个点的值完全依赖于前面的点的值和导数的变化,这种直接依赖关系可能导致误差随着迭代的进行而累积,从而导致稳定性较差。
- 隐式方法中,将下一个点的值也引入到递推公式中,这相当于在每一步迭代中都重新调整轨迹,使得误差不会随着迭代放大。因此,隐式方法的稳定性应当更好。
比较:欧拉法的显/隐式方法
让我们考虑欧拉显式方法。我们知道它的递推式为
ωi+1=ωi+hfi
对于我们的测试方程,这个递推式也就是
ωi+1=ωi+hλωi=(H+1)ωi
那么,我们可以根据等比数列的知识得到
ωi+1=α(1+H)i+1
我们的带有误差的初值为 α∗=α+ϵ,于是我们得到
ϵi+1=ωi+1∗−ωi+1=(1+H)i+1ϵ
为了让误差随着采样数的增加而减小,必须有 ∣1+H∣<1。于是, H 的范围也就是复平面上以 (−1,0i) 为圆心,半径为 1 的圆。
如果我们再考虑欧拉隐式方法,就能得到
⎩⎨⎧ωi+1ϵi+1=(1−H1)i+1α=(1−H1)i+1ϵ
因为我们已经规定了 Re(λ)<0,所以隐式方法总是稳定的!
对微分方程系统的分析
考虑
⎩⎨⎧u1′u2′=9u1+24u2+5cos(t)−31sin(t),u1(0)=34=−24u1−51u2−9cos(t)+31sin(t),u2(0)=32
我们如何选择 h 来保证使用显式欧拉法时的稳定性呢?
考虑将上述方程写成向量的形式。我们记
⎩⎨⎧yAg(t)=(u1u2)=(9−2424−51)=(5cos(t)−31sin(t)−9cos(t)+31sin(t))
那么就有
y′=Ay+g(t)
如果我们考虑对 A 做特征值分解 A=U−1ΛU,那么就有
(Uy)′=Λ(Uy)+(Ug(t))
我们注意到,Λ 是一个对角矩阵,所以此时新的变量 Uy 的两个变量是互相独立的。因此,我们可以直接使用一阶常微分方程中判断稳定性的结论,即:
{∣λ1+1∣<1∣λ2+1∣<1
可以解得 λ1=−3,λ2=−39,因此我们应当取 h<392。
其实我们注意到,对于另一个变量来说,这么小的 h 在求解上还是太浪费了。因此,实际问题中降低计算量的一个思路就是避免产生特征值相差较多的 A。
